Das Wesen der Paginierung, warum sie benötigt wird und wie man sie richtig einrichtet

Paginierung ist die Aufteilung eines großen Datenbestands auf einer bestimmten Ressource zur sequentiellen Anzeige von Inhalten. Einfach ausgedrückt handelt es sich um die Nummerierung von Seiten auf einer Web-Ressource in aufsteigender Reihenfolge, die für den Benutzerkomfort gestaltet ist. Sie ist besonders relevant, um eine Ressource auf Seiten zu unterteilen für Marktplätze, Online-Shops mit einem großen Warenangebot, Sites, die verschiedene Dienstleistungen für die Öffentlichkeit anbieten, Portale, auf denen aktuelle Nachrichten veröffentlicht werden, beliebte Blogs und mehr.
Durch die Nummerierung finden Benutzer leichter zwischen Gruppen von Links den Weg. Die Seitennummerierung kann oben oder unten auf der Website zu sehen sein.
Der Einfluss der Paginierung auf die Suchmaschinenoptimierung (SEO)
Die Segmentierung eines großen Datenbestands in Cluster verwandelt die Seite in eine verständlichere und benutzerfreundlichere Ressource, was die Benutzerfreundlichkeit der Ressource verbessert. Darüber hinaus hängt die Aufnahme wertvoller Seiteninhalte in die Suchmaschinenindizes von einer korrekt konfigurierten Paginierung ab. Das Sammeln, Verarbeiten und Eingeben von Informationen über den Inhalt der Ressource in Suchmaschinen-Datenbanken sowie deren Ergonomie beeinflussen signifikant deren Aufnahme in die Suchergebnisse. Lassen Sie uns dies ausführlicher betrachten.
Website-Benutzerfreundlichkeit
Suchmaschinen möchten, dass die wertvollsten und nützlichsten Inhalte an oberster Stelle angezeigt werden. Zu diesem Zweck verwenden automatisierte Systeme eine Vielzahl von Indikatoren, die es ermöglichen, die Benutzerfreundlichkeit einer Site für Benutzer sowie die Qualität der auf der Site platzierten Inhalte zu bewerten. Wie sich Benutzer auf der Site verhalten und wie bequem die Plattform für sie ist, hängt auch mit der Paginierung zusammen. Lassen Sie uns genauer darauf eingehen.
Seitenerlebnis
Wenn Seiten auf der Website nach und nach geladen werden, trägt dies dazu bei, die Menge an Informationen zu reduzieren, die der Server an den Browser sendet. Dank dieser Tatsache wird die Seite auf Smartphones und Computern schneller geladen. Darüber hinaus ist die Benutzerfreundlichkeit der Seiten ein Ranking-Kriterium, das die Positionen der URL in den Suchergebnissen erhöht.
Verhaltensfaktoren
Die von den Benutzern auf einer Website verbrachte Zeit ist ein indirekter Hinweis auf das Vorhandensein qualitativ hochwertiger Inhalte. Paginierung erleichtert es dem Besucher, mehr Zeit auf dieser Website zu verbringen. Eine Analyse der Suchergebnisse hat gezeigt, dass ein enger Zusammenhang zwischen dem Benutzerverhalten und den Positionen bei Abfragen besteht.
Crawling und Indexierung
Damit Paginierungsseiten in den Suchergebnissen erscheinen, müssen einige Merkmale bekannt sein, von denen die Indexierung der Seiten durch Bots abhängt:
- Einzigartiger Inhalt.
Website-Benutzerfreundlichkeit
Suchmaschinen möchten, dass die wertvollsten und nützlichsten Inhalte an oberster Stelle angezeigt werden. Zu diesem Zweck verwenden automatisierte Systeme eine Vielzahl von Indikatoren, die es ermöglichen, die Benutzerfreundlichkeit einer Site für Benutzer sowie die Qualität der auf der Site platzierten Inhalte zu bewerten. Wie sich Benutzer auf der Site verhalten und wie bequem die Plattform für sie ist, hängt auch mit der Paginierung zusammen. Lassen Sie uns genauer darauf eingehen.
Seitenerlebnis
Wenn Seiten auf der Website nach und nach geladen werden, trägt dies dazu bei, die Menge an Informationen zu reduzieren, die der Server an den Browser sendet. Dank dieser Tatsache wird die Seite auf Smartphones und Computern schneller geladen. Darüber hinaus ist die Benutzerfreundlichkeit der Seiten ein Ranking-Kriterium, das die Positionen der URL in den Suchergebnissen erhöht.
Verhaltensfaktoren
Die von den Benutzern auf einer Website verbrachte Zeit ist ein indirekter Hinweis auf das Vorhandensein qualitativ hochwertiger Inhalte. Paginierung erleichtert es dem Besucher, mehr Zeit auf dieser Website zu verbringen. Eine Analyse der Suchergebnisse hat gezeigt, dass ein enger Zusammenhang zwischen dem Benutzerverhalten und den Positionen bei Abfragen besteht.
Crawling und Indexierung
Damit Paginierungsseiten in den Suchergebnissen erscheinen, müssen einige Merkmale bekannt sein, von denen die Indexierung der Seiten durch Bots abhängt:
- Einzigartiger Inhalt.
Seitenerlebnis
Wenn Seiten auf der Website nach und nach geladen werden, trägt dies dazu bei, die Menge an Informationen zu reduzieren, die der Server an den Browser sendet. Dank dieser Tatsache wird die Seite auf Smartphones und Computern schneller geladen. Darüber hinaus ist die Benutzerfreundlichkeit der Seiten ein Ranking-Kriterium, das die Positionen der URL in den Suchergebnissen erhöht.
Verhaltensfaktoren
Die von den Benutzern auf einer Website verbrachte Zeit ist ein indirekter Hinweis auf das Vorhandensein qualitativ hochwertiger Inhalte. Paginierung erleichtert es dem Besucher, mehr Zeit auf dieser Website zu verbringen. Eine Analyse der Suchergebnisse hat gezeigt, dass ein enger Zusammenhang zwischen dem Benutzerverhalten und den Positionen bei Abfragen besteht.
Crawling und Indexierung
Damit Paginierungsseiten in den Suchergebnissen erscheinen, müssen einige Merkmale bekannt sein, von denen die Indexierung der Seiten durch Bots abhängt:
- Einzigartiger Inhalt.
Verhaltensfaktoren
Die von den Benutzern auf einer Website verbrachte Zeit ist ein indirekter Hinweis auf das Vorhandensein qualitativ hochwertiger Inhalte. Paginierung erleichtert es dem Besucher, mehr Zeit auf dieser Website zu verbringen. Eine Analyse der Suchergebnisse hat gezeigt, dass ein enger Zusammenhang zwischen dem Benutzerverhalten und den Positionen bei Abfragen besteht.
Crawling und Indexierung
Damit Paginierungsseiten in den Suchergebnissen erscheinen, müssen einige Merkmale bekannt sein, von denen die Indexierung der Seiten durch Bots abhängt:
- Einzigartiger Inhalt.
Crawling und Indexierung
Damit Paginierungsseiten in den Suchergebnissen erscheinen, müssen einige Merkmale bekannt sein, von denen die Indexierung der Seiten durch Bots abhängt:
- Einzigartiger Inhalt.
- Einzigartiger Inhalt.
Da Google und Yandex eine Seite aus dem Index entfernen könnten, wenn doppelte Inhalte festgestellt werden, sollte der Site-Betreiber in erster Linie originelle Inhalte auf seiner Website veröffentlichen. Nummerierte Seiten werden von Robotern als separate URLs wahrgenommen. Da Paginierungsseiten jedoch häufig einander ähneln, sollte man ihre Optimierung nicht vergessen. Andernfalls kann der Roboter sie als Duplikate wahrnehmen.
- Crawling-Budget.
Googlebot ist nicht in der Lage, alle Seiten der Ressource zu scannen, die es besucht. Es hat eine begrenzte Anzahl von Seiten pro Besuch. Während es große Sites mit vielen nummerierten Seiten umgeht, könnte es einfach das Limit verpassen, um andere wertvolle URLs zu scannen. Unter solchen Bedingungen wird deren Inhalt im Laufe der Zeit indexiert.
SEO-Paginierungsstrategien
Es gibt mehrere Ansätze, um Robotern zu vermitteln, Paginierungsseiten nicht als Duplikate zu betrachten. Lassen Sie uns ein paar solcher Strategien besprechen.
Indexierung aller nummerierten Seiten und ihrer Inhalte
In diesem Ansatz werden alle Seiten optimiert, um die Suchmaschinenanforderungen zu erfüllen: Einzigartige Inhalte werden ihnen hinzugefügt, und die Konfiguration zwischen einheitlichen Ressourcenindikatoren wird für Webcrawler festgelegt.
Indexierung aller nummerierten Seiten und ihrer Inhalte
In diesem Ansatz werden alle Seiten optimiert, um die Suchmaschinenanforderungen zu erfüllen: Einzigartige Inhalte werden ihnen hinzugefügt, und die Konfiguration zwischen einheitlichen Ressourcenindikatoren wird für Webcrawler festgelegt.
Besonderheiten: Nummerierte Seiten und URLs, die ihnen hinzugefügt werden, werden indexiert und im Seiten-Output sortiert. Die Strategie ist sowohl für kleine als auch für große Paginierungsreihen relevant.
Indexierung einer einzigen einheitlichen Übersichtsseite
Die Strategie basiert auf der Erstellung einer neuen URL, die alle kategorisierte Ergebnisse enthält, die paginiert sind. Benutzer finden diese Seite durch einen Link oder einen Klick auf “Alle anzeigen”. Als Ergebnis muss der Bot, um Inhalte für die Indexierung hinzuzufügen, nur eine URL verarbeiten.
Manchmal kommt es vor, dass die Suchmaschine eine Übereinstimmung auf nummerierten Seiten und “Alle anzeigen” als Duplikate betrachtet. Um dies zu vermeiden, wird ein kanonisches Tag angewendet. Auf allen nummerierten Seiten sollte der Kanonische zur Hauptfilterseite hinzugefügt werden. So versteht der Webcrawler, welcher Inhalt unter Duplikaten zuerst indexiert werden soll.
Besonderheiten: Diese Methode ist für kleine Kategorien relevant, zum Beispiel wenn Ergebnisse von 3-4 nummerierten Seiten angezeigt werden. Für eine große Paginierungskette wird diese Methode keine spürbaren Ergebnisse bringen, da, wenn viele Inhalte auf einer Seite geladen werden, dies ihre Geschwindigkeit erheblich beeinträchtigt.
Schließen von nummerierten Seiten aus der Indexierung
Mit Hilfe des Schließens von Paginierungsseiten in der robots.txt-Datei wird Bots das Indexieren aller Seiten außer der ersten verboten. Dieser Ansatz ermöglicht es, das Crawling-Budget zu sparen, um andere wichtige URLs zu umgehen. Auch mit dieser Methode kann man Seitenkopien leicht verstecken.
Besonderheiten: Dieser Ansatz eignet sich für große Ressourcen, bei denen Inhalte stufenweise angezeigt werden. Der Nachteil der Methode ist, dass, wenn der Bot keine Links auf Paginierungsseiten findet, er möglicherweise die Seiten, auf die sie umleiten, nicht indexiert. Dies betrifft besonders die Fälle, in denen diese URLs nicht auf der Ressourcenkarte (Sitemap) markiert sind.
Paginationsfehler und Wege, sie zu entdecken
Solche Mängel werden rechtzeitig identifiziert, wenn Sie spezifische Tools verwenden. Lassen Sie uns diese im Detail besprechen.
Doppelte Titel- und Beschreibungs-Tags
Eine abgeschlossene Beschreibung und ein Titel sind ein Schritt in Richtung SEO-Optimierung. Verdichtete Daten über die Webseite sind sowohl für gewöhnliche Benutzer in der Suche sichtbar als auch für Roboter beim Scannen. Die Empfehlung von Suchmaschinen ist, allen Seiten der Website einzigartige Titel- und Beschreibungs-Tags zuzuweisen.
Doppelter Inhalt
Roboter bemerken durch den Vergleich der Seiten der Ressource URLs mit nicht einzigartigem Inhalt. Wenn Google oder Yandex Duplikate entdecken, entfernen sie diese URLs aus der Indexierung. Daher sollte der Website-Betreiber Duplikate rechtzeitig verfolgen und beseitigen und damit ihre Site optimieren.
Fehlerhafte Einrichtung von kanonischen Links
Ein Kanonischer ist erforderlich, um Bots zu einem einheitlichen Site-Indikator weiterzuleiten, der für die Indexierung priorisiert wird. Auf Duplikaten/ähnlichen Seiten wird rel=”canonical” angegeben, das auf die kanonische Version umleitet.
Doppelte Titel- und Beschreibungs-Tags
Eine abgeschlossene Beschreibung und ein Titel sind ein Schritt in Richtung SEO-Optimierung. Verdichtete Daten über die Webseite sind sowohl für gewöhnliche Benutzer in der Suche sichtbar als auch für Roboter beim Scannen. Die Empfehlung von Suchmaschinen ist, allen Seiten der Website einzigartige Titel- und Beschreibungs-Tags zuzuweisen.
Doppelter Inhalt
Roboter bemerken durch den Vergleich der Seiten der Ressource URLs mit nicht einzigartigem Inhalt. Wenn Google oder Yandex Duplikate entdecken, entfernen sie diese URLs aus der Indexierung. Daher sollte der Website-Betreiber Duplikate rechtzeitig verfolgen und beseitigen und damit ihre Site optimieren.
Fehlerhafte Einrichtung von kanonischen Links
Ein Kanonischer ist erforderlich, um Bots zu einem einheitlichen Site-Indikator weiterzuleiten, der für die Indexierung priorisiert wird. Auf Duplikaten/ähnlichen Seiten wird rel=”canonical” angegeben, das auf die kanonische Version umleitet.
Doppelter Inhalt
Roboter bemerken durch den Vergleich der Seiten der Ressource URLs mit nicht einzigartigem Inhalt. Wenn Google oder Yandex Duplikate entdecken, entfernen sie diese URLs aus der Indexierung. Daher sollte der Website-Betreiber Duplikate rechtzeitig verfolgen und beseitigen und damit ihre Site optimieren.
Fehlerhafte Einrichtung von kanonischen Links
Ein Kanonischer ist erforderlich, um Bots zu einem einheitlichen Site-Indikator weiterzuleiten, der für die Indexierung priorisiert wird. Auf Duplikaten/ähnlichen Seiten wird rel=”canonical” angegeben, das auf die kanonische Version umleitet.
Fehlerhafte Einrichtung von kanonischen Links
Ein Kanonischer ist erforderlich, um Bots zu einem einheitlichen Site-Indikator weiterzuleiten, der für die Indexierung priorisiert wird. Auf Duplikaten/ähnlichen Seiten wird rel=”canonical” angegeben, das auf die kanonische Version umleitet.
Bei fehlerhafter kanonischer Einrichtung könnten Roboter wertvolle URLs nicht berücksichtigen und Paginierungsseiten aus dem Index entfernen, da sie sie als Duplikate betrachten.
Spezielle Tools zur Erkennung von Paginierungsproblemen
Es gibt mehrere Dienste, die entwickelt wurden, um Fehler im Zusammenhang mit der Optimierung von Ressourcensuche zu finden, die auch Paginierung umfassen. Lassen Sie uns einige von ihnen genauer betrachten.
Google Search Console
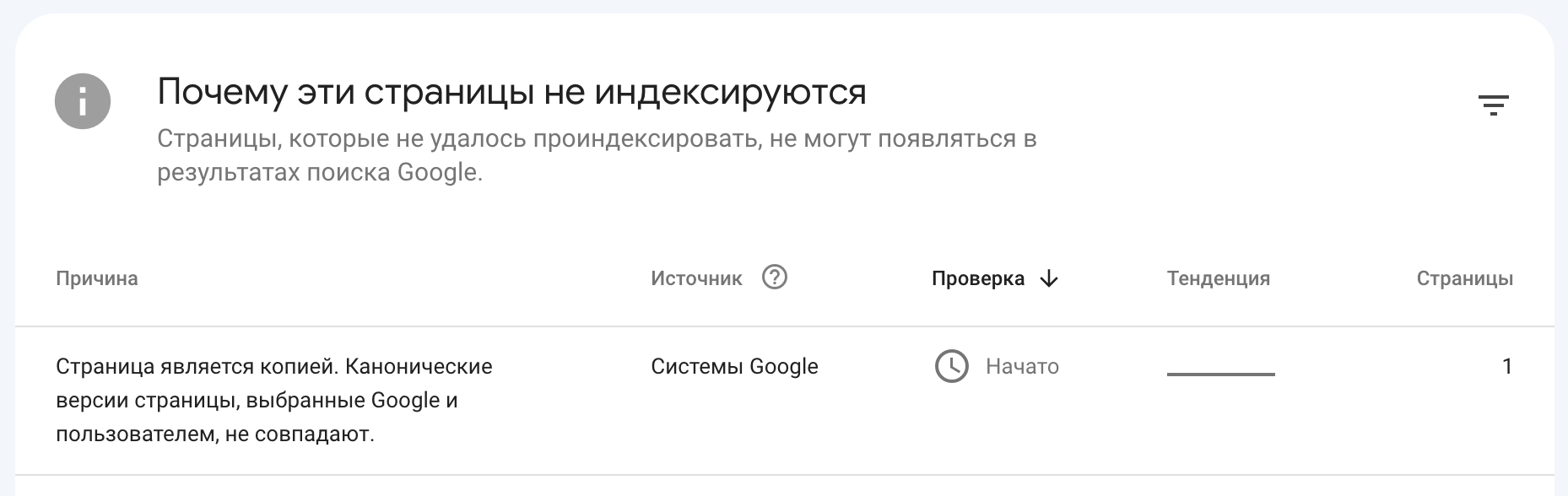
Wenn Sie zum Bereich “Indexing” gehen und dann die Registerkarte “Pages” öffnen, können Sie URLs sehen, die aus dem Index entfernt wurden. Hier können Sie auch Ressourcen-Seiten sehen, die Suchmaschinen als Duplikate betrachteten (solche Seiten erhalten den Status „Seite ist eine Kopie“).
Google Search Console
Wenn Sie zum Bereich “Indexing” gehen und dann die Registerkarte “Pages” öffnen, können Sie URLs sehen, die aus dem Index entfernt wurden. Hier können Sie auch Ressourcen-Seiten sehen, die Suchmaschinen als Duplikate betrachteten (solche Seiten erhalten den Status „Seite ist eine Kopie“).
Außerdem können Sie in der Google Search Console Informationen zu kanonischen Problemen anzeigen.
Yandex.Webmaster
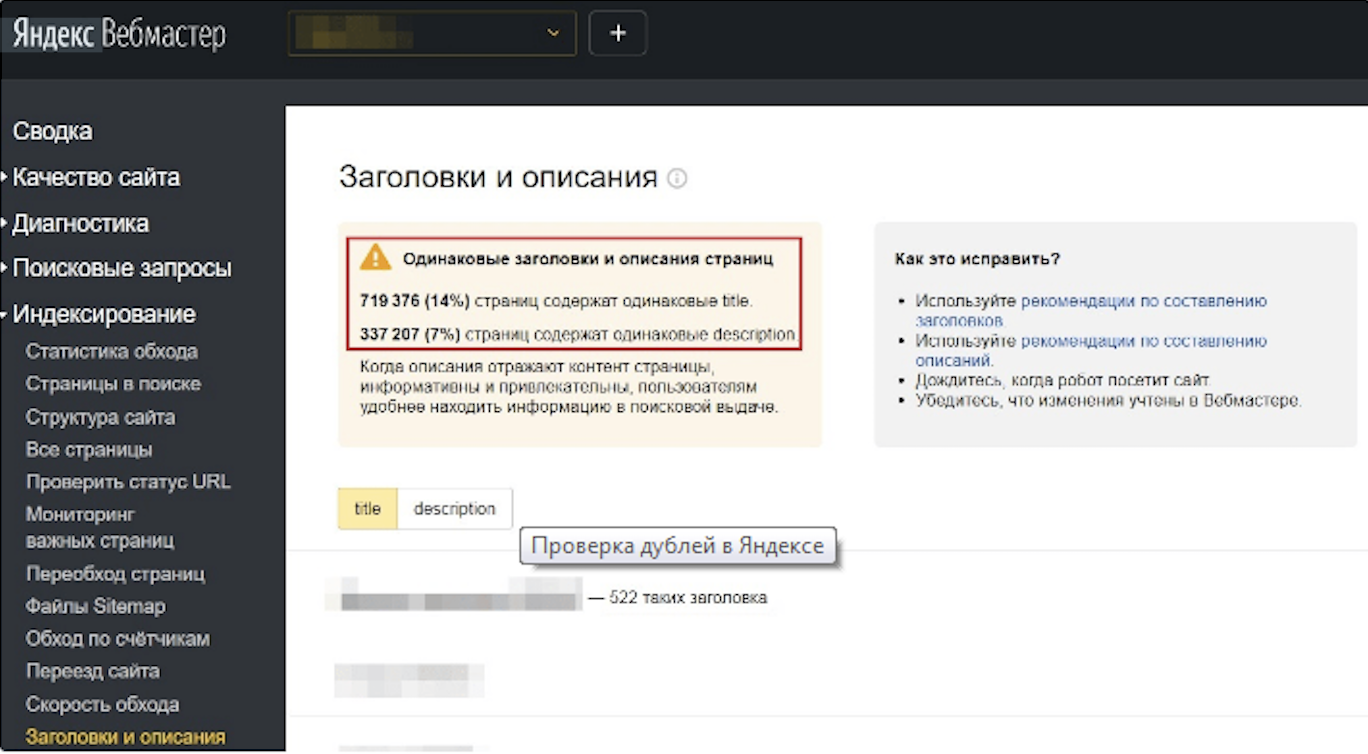
Mit diesem Dienst können Sie sehen, welche Seiten der Yandex-Roboter als Duplikate ansah, Kopien von Titeln und Beschreibungen finden. Benutzer können URLs entdecken, die aus dem Index ausgeschlossen wurden, indem sie den Bereich “Indexing” besuchen. Einer Webseite wird der Status „Duplikat“ zugewiesen, wenn Webcrawler dort nicht einzigartigen Inhalt gefunden haben. Auch Duplikate von Titeln und Beschreibungen können hier durch Klicken auf den Tab “Überschriften und Beschreibungen” gesehen werden.
Programme für detaillierte Audits
Es existieren spezielle Tools, die es bei Anwendung ermöglichen, ein detailliertes Audit der Site durchzuführen, einschließlich verschiedener technischer Parameter. Zu solchen Tools gehört Screaming Frog, das in der Lage ist, eine große Anzahl von Parametern zu überprüfen und Mittel zur Lösung von Problemen bereitzustellen. Dieses Programm identifiziert viele Probleme: doppelte Titel und Beschreibungen, kanonische Probleme und andere.
Einrichtung der Paginierung
Dafür sollten die folgenden Schritte durchgeführt werden:
Aufgabe 1. Indexierung aller Paginierungsseiten
Optimierung ist wichtig für die erfolgreiche Indexierung der Seiten durch Suchmaschinen. Es ist notwendig, dass Seiten unterschiedliche URLs, Inhalte, Titel-Tags und Beschreibungen haben.
Einrichtung der Paginierung
Dafür sollten die folgenden Schritte durchgeführt werden:
Aufgabe 1. Indexierung aller Paginierungsseiten
Optimierung ist wichtig für die erfolgreiche Indexierung der Seiten durch Suchmaschinen. Es ist notwendig, dass Seiten unterschiedliche URLs, Inhalte, Titel-Tags und Beschreibungen haben.
Aufgabe 1. Indexierung aller Paginierungsseiten
Optimierung ist wichtig für die erfolgreiche Indexierung der Seiten durch Suchmaschinen. Es ist notwendig, dass Seiten unterschiedliche URLs, Inhalte, Titel-Tags und Beschreibungen haben.
Für die Optimierung der Paginierungsseite sollten Sie Folgendes tun:
- Erstellen Sie nummerierte Seiten mit originalen Adressen.
Dafür verwenden Sie die Verschachtelung einheitlicher Ressourcen-Identifikatoren basierend auf url/n oder Abfrage-Parametern ?page=n. Hier wird n die fortlaufende Seitennummer bezeichnen.
Vergessen Sie die Paginierungs-ID #: Google kann Daten, die danach kommen, nicht erkennen. Das bedeutet, dass Roboter die URL-Adresse als bereits verarbeitet betrachten könnten und sie nicht indexieren.
- Verknüpfen Sie Paginierungsseiten miteinander.
Verwenden Sie ein href, um im Code jeder Seite einen Link zur nächsten URL anzugeben. Dies erleichtert es Bots, den aufgeteilten Inhalt zu scannen. Stellen Sie auch sicher, dass ein Link zur ersten Seite enthalten ist. Dies bietet den Bots einen Hinweis, welche Seite sie während der Ranking-Prozesse auswählen sollten.
- Erstellen Sie Titel und Beschreibungen für Seiten.
Auch wenn Google es erlaubt, identische Titel und Beschreibungen während der Paginierung zu verwenden, müssen die Titel und Beschreibungen dennoch abgeschlossen werden, um den Seiteninhalt einzigartig zu machen.
- Weisen Sie jeder Paginierungsseite ein Kanonisches zu.
Geben Sie dafür im Tag das kanonische Attribut und den Link zu dieser Seite an.
Aufgabe 2. Indexierung einer einzigen übergreifenden “Alle anzeigen”-Seite.
Mit diesem Ansatz ist es möglich, “Alle anzeigen” effektiv mit Paginierungsergebnissen für die Anzeige in Suchergebnissen zu optimieren und höhere Positionen einzunehmen. Dafür ist es notwendig:
- Erstellen Sie eine Seite, die alle Ergebnisse der Paginierungsseiten enthält.
- Erstellen Sie eine Seite, die alle Ergebnisse der Paginierungsseiten enthält.
Web-Ressourcen können mehrere solcher Seiten haben. Dies hängt davon ab, wie viele nummerierte Blöcke auf der Site platziert sind.
- Geben Sie “Alle anzeigen” als kanonisch an.
Stellen Sie sicher, dass jede Paginierungsseite im Tag die kanonische Eigenschaft enthält. Berücksichtigt man dies, führen die Roboter zur allgemeinen URL, die für die Indexierung priorisiert ist.
- Optimieren Sie so, dass “Alle anzeigen” schneller lädt.
Je schneller der Inhalt auf PCs, Smartphones und anderen Geräten geladen wird, desto wahrscheinlicher ist es, dass eine URL bessere Positionen im Output erhält. Mit Hilfe verschiedener Dienste, beispielsweise PageSpeed Insights, können Sie Faktoren identifizieren, die das Laden von “Alle anzeigen” verlangsamen. Nach Erhalt der Ergebnisse beseitigen Sie die Ursachen, die sich negativ auf die Seitenleistung auswirken.
Aufgabe 3. Verbot der Indexierung von Paginierungsseiten
Webcrawlern muss angedeutet werden, dass das Verbot der Indexierung nur Paginierungsseiten betreffen sollte. Unterdessen sollten die URLs von Waren und anderen Ergebnissen, die in Blöcke aufgeteilt sind, sichtbar für Webcrawler sein.
Dafür muss folgendes gemacht werden:
- Erstellen Sie eine Einschränkung bei der Indexierung aller Paginierungsseiten außer der ersten.
Dies wird durch zwei Methoden erreicht:
- Beschränken Sie die Indexierung mit Robots.
Auf Seiten, außer der ersten, fügt der Block Meta-Name=robots mit noindex, follow hinzu. Diese Methode erlaubt es, die Seitenindexierung zu verbieten, während dem Benutzer ermöglicht wird, auf Links zu folgen, die darauf platziert sind.
- Kanonisch zur Hauptseite aller Produkte, die den höchsten Wert für die Indexierung repräsentiert.
Auf jeder Seite, die der Paginierung unterliegt, wird ein kanonisches Attribut vorgeschrieben, um auf die erste Seite der Sequenz umzuleiten.
- Optimierung der ersten Paginierungsseite.
Damit die Seite in den Index aufgenommen wird, sollte man sich mit Ranking-Problemen befassen: zuerst sollte man auf Inhalte und Tags achten.
Schlussfolgerungen
Paginierung ist eine sequentielle Nummerierung von Seiten, die dazu beiträgt, die Benutzerfreundlichkeit der Site zu verbessern.
Es gibt spezifische Methoden, mit deren Hilfe die Einstellung der Paginierungsseiten durchgeführt wird:
- Indexierung aller Paginierungsseiten;
- Indexierung “Alle anzeigen”;
- Einschränkung der Indexierung jeder nummerierten Seite außer der ersten.
Um Paginierungsprobleme zu identifizieren, wenden Sie Tools an, die für diesen Zweck entwickelt wurden, wie Yandex.Webmaster-Abschnitte, Google Search Console oder verwenden Sie Screaming Frog für die gründlichste Website-Analyse.



