Todo Sobre la Etiqueta rel=canonical y Cómo Aplicarla

Una visión general comprensiva de la etiqueta rel = “canonical” – su propósito, métodos de aplicación y problemas encontrados por los optimizadores. Un estudio de la información necesaria para trabajar eficazmente con etiquetas canónicas. Los datos presentados a continuación están destinados a individuos que están comenzando a explorar este tema.
Rel canónico – conceptos clave y áreas de aplicación
Usar el mismo contenido en múltiples páginas puede llevar a sanciones serias de los motores de búsqueda. Sin embargo, en algunas situaciones, tal uso del texto puede estar justificado:
- usar el sitio con y sin www;
- inclusión de una página en dos o más categorías simultáneamente;
- filtrado y selección de productos por atributos en un catálogo.
Considerando el último ejemplo, a menudo las páginas son parcialmente idénticas. Una podría tener un filtro activado por tipo de producto, y otra por su costo. Sin embargo, esto no agrega unicidad.
Para evitar sanciones, es importante determinar qué versión se considerará primaria o canónica, y cuál será un duplicado. En programación, se creó una etiqueta especial con el mismo nombre – rel = “canonical” – para este propósito. Ayuda a prevenir sanciones debido al contenido duplicado.
La página canónica tiene la URL principal. Otras páginas, donde se usa el mismo contenido, están marcadas con rel = “canonical”. Esto permite al bot reconocer la página duplicada.
¿Por qué especificar la versión primaria?
rel = “canonical” – este es un atributo esencial que debe añadirse a las páginas duplicadas. Este requisito no solo ayuda a eliminar el riesgo de sanciones sino que también ayuda a:
- reducir gastos innecesarios, ya que puedes disminuir la proporción del presupuesto de rastreo asignado a duplicados;
- señalizar la URL que no solo aparecerá en los resultados de búsqueda sino que también recibirá todas las señales;
- distribuir la equidad de los enlaces a la página o sitio necesario.
Puedes estudiar los datos sobre URLs canónicas en más detalle a través de dos servidores – Yandex y Google. La información se muestra en la pestaña de ayuda.
Para mayor claridad, es necesario examinar los conceptos con un ejemplo. Proporcionemos uno. Un sitio tiene una página que se puede acceder a través de tres direcciones diferentes, incluyendo:
- https://mi-sitio.com/blog/categorias/144;
- https://mi-sitio.com/blog/categorias/foto;
- https://mi-sitio.com/blog/categorias/noticias.
Si es necesario que https://mi-sitio.com/blog/categorias/foto sea considerada la página canónica, no debería reemplazarse. Mientras tanto, el código de los duplicados debe incluir – . Este paso resultará en que solo uno de los tres enlaces sea clasificado en los resultados de búsqueda – https://mi-sitio.com/blog/categorias/foto.
Páginas Índice y No Canónicas
Los expertos de Yandex confirman que existe la posibilidad de que páginas no canónicas aparezcan en los resultados de búsqueda. Sin embargo, esto solo puede suceder en algunos casos:
- alto nivel de relevancia;
- diferencia en el contenido entre una página no canónica y una canónica.
Mientras tanto, el Webmaster ahora presenta nuevas designaciones de páginas que permiten a los usuarios ver el tipo deseado. Por ejemplo, si necesitas estudiar páginas canónicas, deberías encontrar la línea con la etiqueta canónica correspondiente en la columna “Páginas en búsqueda”.
Los especialistas de Google sostienen una opinión similar. Según ellos, el sistema no siempre es capaz de reconocer solo páginas canónicas. Esto se debe a que la etiqueta canónica no es una directiva sino que se considera una recomendación. Por lo tanto, si el sistema reconoce una URL no canónica como más relevante, la mostrará en los resultados de búsqueda. Sin embargo, usar el atributo canónico reduce la probabilidad de que el sistema reconozca la URL de página incorrecta.
¡Nota! A pesar de estas características, las páginas canónicas tienen prioridad en los resultados de búsqueda. Sin embargo, una configuración incorrecta de la etiqueta puede conllevar problemas de indexación. Por lo tanto, es importante entender las circunstancias bajo las cuales el uso de tal etiqueta es estrictamente necesario.
Situaciones donde la presencia de una etiqueta canónica es obligatoria
La razón principal para la presencia de una etiqueta canónica es la existencia de información idéntica en múltiples páginas. En otras palabras, el mismo contenido es servido por varias URLs simultáneamente. En tales duplicados, se debe añadir una etiqueta canónica.
Creación de duplicados de página
Las páginas duplicadas con contenido similar se encuentran más comúnmente en los recursos de tiendas en línea. Allí, es posible ordenar productos por un criterio específico. Podemos examinar la situación usando una tienda de muebles como ejemplo.
- Ejemplo número uno. Si una silla en el surtido está disponible en varios colores, se puede usar una etiqueta para resaltar el modelo (su página) que es más popular entre los clientes. Mientras tanto, los usuarios tendrán acceso a todos los productos. Solo el enlace al color seleccionado tendrá jugo de enlaces y otras señales.
- Otra situación es cuando una página de producto puede pertenecer a varias categorías a la vez. Como resultado, aparecen múltiples URLs que se relacionan con un solo producto. En este caso, es necesario elegir una página que tenga alta demanda. Es esta página la que se añade al código de la página duplicada. Esto se hace usando la etiqueta canónica rel = “canonical”.
Paginación de Páginas

Al cambiar de página, se crean URLs duplicadas. A menudo ocurren errores de indexación debido a problemas para determinar la página principal. Esto sucede porque la elección simplemente recae en la primera página. Consideremos varias opciones.
- Primer ejemplo. Si existe una opción “Ver todo”, entonces toda la información listada en ella pertenecerá a la página canónica. Para ello, coloca rel = “canonical” en el código de la página de Paginación.
-
- Para http://mi-sitio.com/blog/categorias/foto-2, la URL requerida es – <link rel=”canonical” href=”http://mi-sitio.com/blog/categorias/foto-2/ver-todo”>.
- Segundo ejemplo. Si la opción “Ver todo” no está disponible, entonces un tipo canónico se añade a todas las páginas.
-
- Para http://mi-sitio.com/blog/categorias/foto-2, el canónico será <link rel=”canonical” href=”http://blog/categorias/foto-2″>.
- Tercer ejemplo. Algunos expertos creen que especificar un canónico a sí mismo resultará en que todas las páginas de paginación se muestren en los resultados de búsqueda. Sin embargo, esto solo es aceptable en situaciones donde son aceptables descripciones y títulos idénticos en páginas con contenido diferente. Se recomienda restringir las páginas de paginación para este propósito. Usa follow o noindex. Disallow debería ser usado en el archivo de robots. Esto limitará la indexación pero permitirá seguir los enlaces.
Sin embargo, es importante recordar que noindex es compatible solo con Yandex; esta opción no es adecuada para Google.
Un sitio y direcciones posibles
Las direcciones se determinan según el tipo de sitio:
- https://mi-sitio.com/;
- https://www.mi-sitio.com/;
- http://mi-sitio.com/;
- http://www.mi-sitio.com/.
Sin embargo, para el motor de búsqueda, esto no será un recurso sino tres separados. Para corregir esto, debes añadir un canónico. Esto ayudará a evitar problemas con el escaneo y la indexación, y también establecer una redirección 301 a la versión principal del sitio.
URL optimizados para móviles
Google ha cambiado su política de búsqueda haciendo de las versiones móviles de sitios web el enfoque principal. Este sistema se llama Mobile-First Indexing. Para entender las condiciones principales donde el uso de la etiqueta canónica es necesario, es esencial estudiar la opinión del experto líder de Google – John Mueller.
Si existe una versión móvil m.naturaleza.ru, deberías añadir una etiqueta para enlazar a la página de escritorio – rel = “canonical”. Para el escritorio, usa rel=alternate. Si se cumplen todas las condiciones correctamente, el bot reconocerá la versión móvil como canónica o primaria. No importa que haya una versión de escritorio en el código. Estas configuraciones no están sujetas a cambio si se aplican en Sitemap.xml.
URL del país
A menudo, los sitios web se crean con múltiples URLs para cubrir muchos países a la vez, mientras tienen el mismo contenido en un idioma. En tales casos, no solo deberías seleccionar una página canónica sino también asegurarte de la presencia de referencias a todos los duplicados.
Sin embargo, si se utilizan diferentes idiomas en cada URL, debería utilizarse hreflang. Luego, el motor de búsqueda podrá mostrar resultados separados.
¡Nota! La etiqueta hreflang solo debería usarse si es necesario especificar páginas adicionales con información idéntica. Sin embargo, se llevan a cabo en otro idioma o para una región separada.
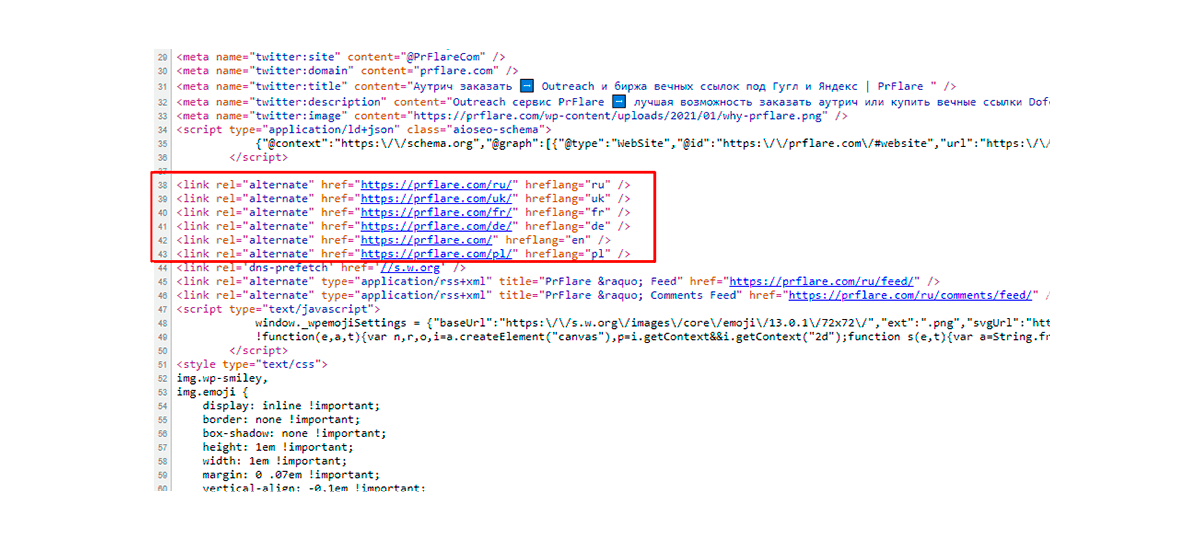
El cambio de Google hacia sistemas orientados a móviles ha hecho obligatorio crear configuraciones hreflang adecuadas. Estas incluyen la regla principal – etiquetas móviles para URLs móviles y etiquetas de escritorio para URLs de escritorio.
Registros
Si las direcciones están marcadas en diferentes casos, el motor de búsqueda puede reconocerlas como diferentes. Es necesario usar minúsculas. Esto ayudará a confirmar la identidad de los enlaces.
Formas de configurar eficazmente el canónico
Para configurar, es necesario destacar la página entre los duplicados, que será considerada la principal o canónica. Luego se introduce en un atributo. Por ejemplo, <link rel=”canonical” href=”http://miwebsite.com/blog/categorias/foto-2/”>. Este atributo se añade a las páginas duplicadas. Hay varias opciones, cada una con sus propias características y ventajas.
Usar un plugin CMS
Para automatizar los parámetros canónicos, se utiliza funcionalidad o plugins únicos en CMS. Para mayor claridad, consideremos unos ejemplos:
- Plugin Yoast SEO. Permite ajustar páginas canónicas en WordPress.
- Plugin de Joomla. La función SEF está disponible, la cual añade automáticamente una etiqueta rel = “canonical”. Al mismo tiempo, se especifica la página principal con una URL amigable.
- Plugin de OpenCart. Configura URLs SEO seleccionando productos basados en parámetros.
Además de los listados, existen otras opciones. En la práctica, examinaremos la opción más común para CMS – WordPress.
WordPress – principales parámetros de configuración
Para añadir un canónico automáticamente, se requiere el plugin Yoast SEO. Todos los parámetros de configuración se muestran en la sección “Avanzado”. En la versión en inglés – “Advanced”. La acción principal es introducir la URL principal de la página. Después de eso, el plugin añade nofollow o noindex a la página. Al mismo tiempo, se configura el canónico para evitar más problemas en la salida del sitio.
Hay otros métodos si la opción presentada no es adecuada.
Usar una página HTML
Esta opción implica añadir una etiqueta rel = “canonical” a la sección <head> de una página duplicada. Visualmente, se ve así:
- Para https://mi-sitio.com/*utm_content, el enlace canónico será https://mi-sitio.com/. Luego necesitas introducir <link rel=”canonical” href=”http://mi-sitio.com/”> en el recurso https://mi-sitio.com/*utm_content.
HTTP para Cabecera
La opción presentada arriba no siempre es factible de implementar en la práctica, especialmente en ausencia de <head>. Por lo tanto, se recomienda conseguir acceso a la configuración del servidor. Después de eso, puedes añadir a HTTP vía PHP o .htaccess.
Si se hace una solicitud de archivo duplicado, el servidor debería mostrar la versión principal.
Considera este ejemplo: La información fue compilada en forma de guía, y para la conveniencia del usuario, se puede descargar del blog. El tipo de archivo es PDF. El resultado será:
- Content-Type: application/pdf
- Link: <http://mi-sitio.com/blog/etiquetas-canonicas/>; rel=”canonical”
Este algoritmo puede aplicarse cuando se trabaja con otras páginas.
Mapa del Sitio
Cualquier motor de búsqueda con configuraciones predeterminadas analiza los enlaces en el archivo XML como canónicos. Algunos servicios, como Google, hacen obligatorio aplicar solo enlaces canónicos en el mapa del sitio. Sin embargo, este elemento actúa meramente como una lista de recomendaciones. Algunos motores de búsqueda no lo tienen en cuenta.
Uso del 301 (redirección)
Otra forma de resolver el problema es usando una redirección 301. Esto es adecuado cuando se puede acceder al sitio a través de múltiples direcciones, incluyendo:
- https://mi-sitio.com/;
- https://www.mi-sitio.com/;
- http://mi-sitio.com/;
- http://www.mi-sitio.com/.
La primera opción se marca como canónica, y se configuran redirecciones para las demás.
Uso de enlaces como una adición
Según John Mueller, se necesitan ciertas señales para determinar la dirección canónica. Los motores de búsqueda usan estas señales. Por ejemplo, si hay dos opciones de dirección https://mi-sitio.com/ y http://www.mi-sitio.com/, Google elegirá la primera. Sin embargo, a menudo prefiere una dirección más atractiva. Si solo se muestra un enlace canónico, el sistema puede seleccionar otra, considerada más óptima.
Si las configuraciones se definen incorrectamente, esto causará problemas serios durante la indexación. En tales situaciones, los optimizadores pueden cometer varios errores en su trabajo.
Problemas en la configuración canónica
- La regla de una sola página
- La regla principal para una configuración efectiva es que 1 página corresponda a una sola dirección canónica. Si esta regla no se sigue y se crean varias, existe el riesgo de que la página sea ignorada por el motor de búsqueda. Por lo tanto, es importante verificar la corrección de las configuraciones canónicas. Para esto, necesitas examinar cuidadosamente la implementación del plugin CMS.
- Una página – diferentes URLs canónicas
- A pesar de la interpretación similar al punto anterior, la esencia aquí es diferente. Explica que al usar varios métodos para especificar el canónico, debes asegurarte de que el enlace a la página principal sea consistente entre ellos.
- Secuencia de páginas canónicas – configuraciones principales
- Si se especifica una página principal diferente como canónica para una página principal, el motor de búsqueda no considerará esa dirección canónica. Por ejemplo, para mi-sitio.com/1, hay un enlace canónico mi-sitio.com/2, y para ello, mi-sitio.com/3.
Colocación de rel = “canonical”
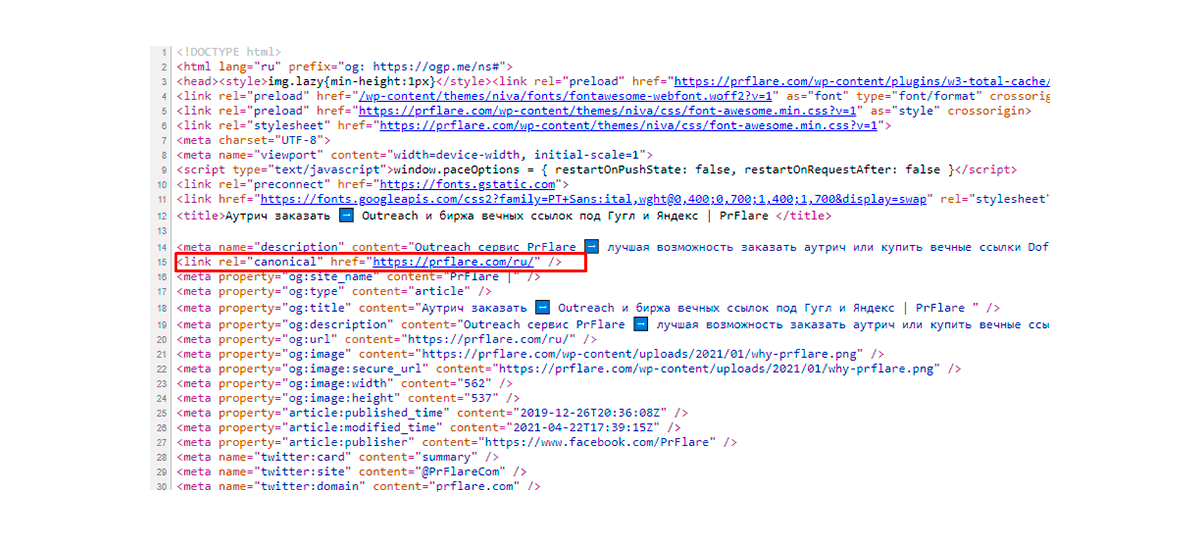
La etiqueta rel = “canonical” solo debería colocarse en la cabeza. Si se coloca en otras áreas, el bot de búsqueda no las considerará. Existe el riesgo de que toda la página sea ignorada.
La primera página de paginación – canónica
Si de todas las páginas de paginación solo la primera está designada como canónica, se excluirá la indexación del resto. El artículo presenta varias opciones para rectificar la situación. Una opción popular es asignar la página con la función ‘Ver todo’ como canónica. La segunda opción es especificar un canónico individual para cada página.
Sin embargo, existe la posibilidad de excluir el uso de la etiqueta canónica y dejar de indexar. La redirección aún estará disponible. Para lograr esto, necesitas:
- Usar disallow para /foto.
- Aplicar noindex o follow para la paginación.
Este método de configuración se utiliza en situaciones donde hay un riesgo de resultados negativos debido al uso de todas las páginas de paginación en la emisión con Descripciones y Títulos idénticos.
URL Canónica – una alternativa a la redirección 301
Aunque se puede decir que la función de una redirección 301 y una etiqueta canónica son idénticas, no se recomienda intercambiarlas. La primera está dirigida a dirigir el tráfico a una sola página, mientras que la segunda oculta de la indexación. Sin embargo, el uso de rel = “canonical” no limitará la obtención de tráfico o actividad.
La página principal actúa como canónica
No se recomienda configurar el enlace canónico de tal manera que se convierta en el principal para el sitio. Esto resultará en que los bots de búsqueda ignoren todas las demás páginas, centrándose en la página de inicio.
Consecuencias de ocultar la página canónica de la indexación
Si la página preferida no está indexada, no podrá participar en la formación de resultados de búsqueda. El mismo resultado ocurrirá si existen otras razones para las restricciones del motor de búsqueda. En tales circunstancias, se elegirá una página no canónica.
Formas de verificar el canónico
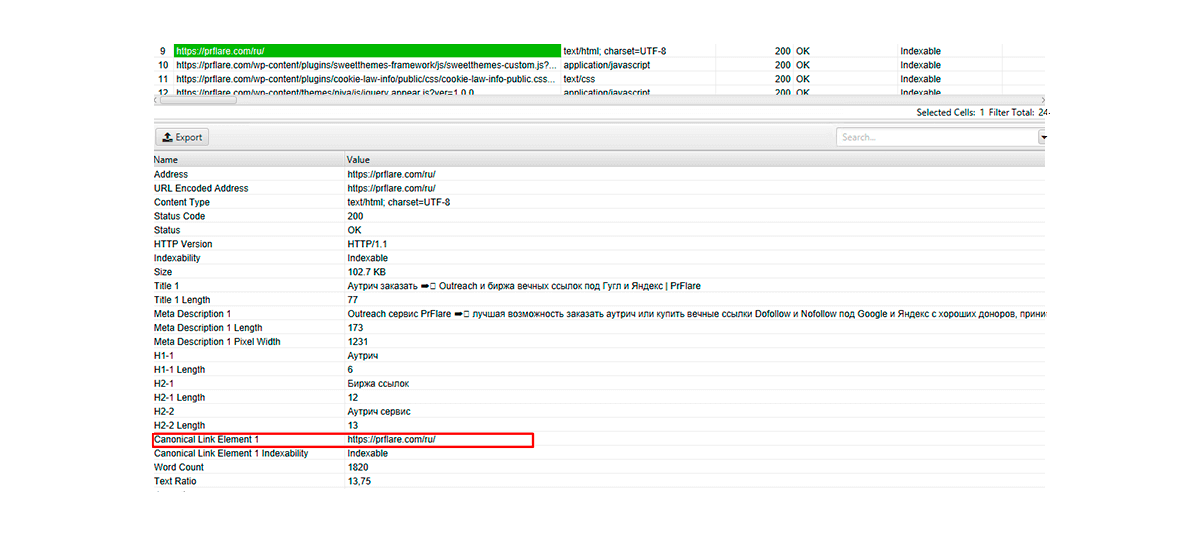
Para verificar si la configuración de la página canónica se realizó correctamente, puedes usar el programa de escritorio Screaming Frog SEO Spider. Resaltará la página que Google reconoce como la principal.
Para Yandex, el camino de verificación es diferente. Webmaster será adecuado para tales propósitos. Eliminará todos los duplicados de la búsqueda, dejando solo el enlace canónico. Esta información se puede encontrar en la sección ‘Indexación’. Todas las páginas excluidas se muestran en la sección del mismo nombre.
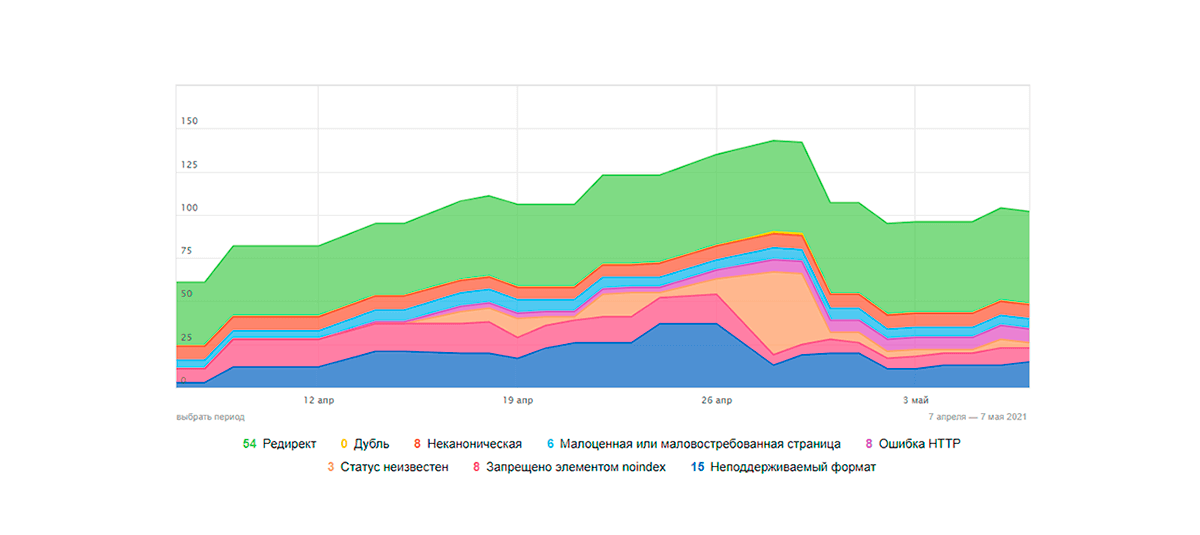
Nuestra Opinión
Los ejemplos anteriores demuestran la importancia de los atributos canónicos. Si alguien todavía duda de si las direcciones canónicas funcionan, el caso mencionado anteriormente debería disipar sus dudas. Si tienes algo que añadir sobre el tema discutido, te invitamos a compartir tu experiencia con la implementación canónica en práctica en los comentarios.



