Google Supplemental ou Connexe : Ce que c’est et Comment Éviter que Vos Pages y Finissent

Google supplément est un index supplémentaire dans le système de recherche, où finissent souvent des sections de certains projets. Pour une personne effectuant une recherche sur Internet, elles deviennent invisibles. En conséquence, les utilisateurs ne reçoivent pas tous les résultats possibles, et le site lui-même progresse très lentement.
Résultats supplémentaires ou “Google Supplemental”
Google s’efforce toujours d’offrir à ses utilisateurs seulement les meilleurs résultats – ceux qui apportent une utilité maximale et contiennent les informations nécessaires. Pour le moteur de recherche, toutes les pages sont divisées en deux parties – principale et supplémentaire. Si une certaine page est évaluée par le moteur de recherche comme ayant une faible valeur informationnelle, elle prend sa place dans l’index supplémentaire de la base de données de Google.
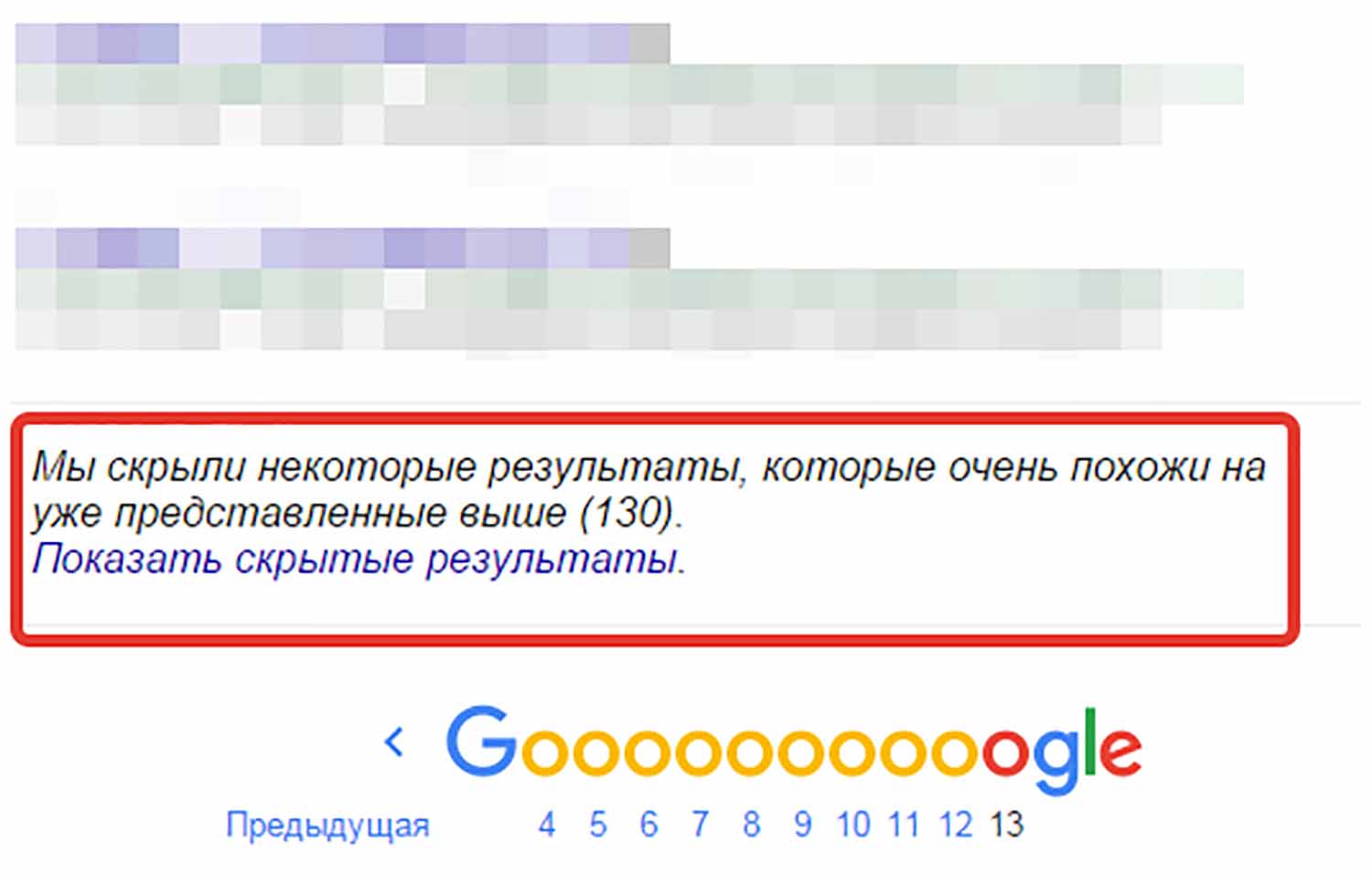
Pourquoi “Google simplement” ? Les spécialistes parlant en russe trouvent plus facile et plus confortable de s’y référer comme “supplémentaire” plutôt que “supplémentaire”, ils ont donc inventé ce jargon pour eux-mêmes. Une telle simplification des termes est une pratique courante pour les spécialistes SEO. Ainsi, lorsque le système de recherche trouve des ressources web occupant une place dans l’index supplémentaire, l’utilisateur voit une phrase indiquant que certains résultats étaient cachés en raison de leur similitude avec des résultats existants.
Pourquoi certaines ressources sont-elles déplacées vers l’index supplémentaire ?
Les raisons pour lesquelles certaines pages sont cachées de l’utilisateur sont assez nombreuses. En voici quelques-unes :
- Texte non unique. Google dispose d’un filtre intégré connu sous le nom de Panda, dont la tâche est de vérifier l’unicité du contenu. De plus, il prend en compte les doublons trouvés dans les limites d’un même site. Il recommande de bloquer toutes les pages contenant du matériel dupliqué du processus d’indexation dans le fichier robots.txt.
- Problèmes de structure du site. Tout site doit avoir une structure logique. S’il y a des problèmes à ce sujet, la page sera immédiatement envoyée à l’index supplémentaire.
- Liens vers des ressources prohibées. C’est la situation où un site contient des liens vers ces ressources web qui sont prohibées par Google.
- Faible poids de la ressource web. Un tel problème peut survenir en raison d’un maillage incorrect au sein de la page elle-même.
- Présence de liens dangereux. Les liens placés sur le site doivent uniquement contenir des pages vérifiées et autorisées. Si un profil de lien a une faible qualité, il n’y a pratiquement aucune confiance en une telle ressource.
- Faible valeur informationnelle de la page. Un tel verdict peut être rendu si le texte est très court, présente un fort pourcentage de duplication ou si une traduction automatique a été utilisée.
- Thématique étrange de la page. C’est la situation où une page distincte sur le site contient des informations qui ont des différences cardinales avec le thème de l’ensemble du site.
- Absence de titre et de description. Si ces balises meta sont totalement absentes ou non uniques, la page a toutes les chances d’être envoyée aux résultats supplémentaires.
Comment comprendre qu’une ressource web a atterri dans le simplement de Google ?
Pour établir qu’une ressource web est dans l’index supplémentaire, vous devez utiliser l’opérateur site. Il est appliqué avec l’URL du site.
Dans le projet sélectionné, un nombre spécifique de pages sera indexé. À la fin de la liste de tous les résultats, l’utilisateur verra qu’un certain pourcentage d’entre eux ont été cachés.
Pourquoi atterrir dans des résultats supplémentaires affecte négativement la popularité du site
Atterrir dans l’index supplémentaire conduit aux conséquences suivantes :
La page reste cachée des utilisateurs et, par conséquent, elle n’aura pas de visiteurs. Il n’y a qu’une seule exception à cette règle – si l’index principal ne peut pas fournir les résultats demandés par l’utilisateur, le moteur de recherche signale qu’il y en a d’autres.
Même si des clés du noyau sémantique sont ajoutées au site Web, elles resteront inaperçues et ne pourront pas garantir des visites d’utilisateurs.
Une ressource contenant un nombre excessif de pages dans l’index simplement sera loin d’être sur les premières lignes des résultats de recherche. Par conséquent, son trafic diminuera considérablement. Pour que le projet évolue et fournisse des résultats, il est nécessaire de retirer les pages de l’index supplémentaire.
Comment transférer des ressources web de l’index supplémentaire vers le principal ?
Pour que les pages disparaissent du supplément de Google, certaines actions importantes doivent être entreprises :
Écoutez les recommandations de Google et refaites le contenu – éditez le texte, assurez son unicité jusqu’à 100%, fournissez une bonne structure, informativité et utilité. De plus, il est particulièrement important de s’assurer que le titre et la description sont corrects et uniques.
Assurez une structure de site cohérente avec 3-4 niveaux de profondeur.
Appliquez la balise “rel=canonical” afin que les moteurs de recherche puissent trouver les pages requises.
Dans le document robots.txt, cachez de l’indexation les pages contenant des informations techniques ou des données qui ne représentent pas de valeur pour l’utilisateur (pages avec classement des produits ou fichiers système).
Résumons :
- Aujourd’hui, nous avons exploré ce que représente le Google supplément. Toutes les pages dirigées vers “simplement” seront situées après celles du primaire, et l’utilisateur peut les voir s’il souhaite se familiariser avec les résultats supplémentaires.
- Si les pages d’un site sont dans le supplément de Google, elles seront cachées des utilisateurs, et sa promotion deviendra pratiquement impossible.
- Pour que les pages soient déplacées de l’index supplémentaire vers le principal, leur contenu doit être amélioré. Il est crucial d’assurer une bonne unicité du contenu, sa qualité, de ne pas avoir de liens douteux sur le site, et globalement de se conformer aux directives de Google.



