L’essence de la pagination, pourquoi elle est nécessaire et comment l’implémenter correctement

La pagination est la division d’un grand ensemble de données sur une ressource spécifique pour l’affichage séquentiel du contenu. En termes simples, il s’agit d’une numérotation des pages sur une ressource web par ordre croissant, conçue pour la commodité de l’utilisateur. Elle est particulièrement pertinente pour diviser une ressource en pages pour les places de marché, les boutiques en ligne avec un large éventail de produits, les sites proposant divers services au public, les portails où sont publiées les actualités les plus récentes, les blogs populaires, et plus encore.
Grâce à la numérotation, les utilisateurs trouvent plus facilement à naviguer entre les groupes de liens. La numérotation des pages peut être vue en haut ou en bas du site.
L’impact de la pagination sur le référencement (SEO)
Segmenter un grand ensemble de données en clusters rend le site plus compréhensible et convivial, améliorant l’ergonomie de la ressource. De plus, l’inclusion dans les index des moteurs de recherche de contenu précieux dépend d’une pagination correctement configurée. La collecte, le traitement et l’entrée de l’information sur le contenu de la ressource dans les bases de données des moteurs de recherche, ainsi que son ergonomie, affectent considérablement son inclusion dans les résultats de recherche. Examinons cela plus en détail.
Ergonomie du site
Les moteurs de recherche veulent que le contenu le plus précieux et utile soit affiché dans les premiers résultats. Pour cela, les systèmes automatisés utilisent un grand nombre d’indicateurs qui permettent d’évaluer la commodité d’un site pour les utilisateurs, ainsi que la qualité du contenu proposé. Comment les utilisateurs se comportent sur le site et à quel point la plateforme leur est pratique sont également liés à la pagination. Concentrons-nous sur cela plus en détail.
Expérience de la Page
Lorsque les pages se chargent sur le site progressivement, cela aide à réduire la quantité d’information que le serveur envoie au navigateur. Grâce à cela, sur les smartphones et les ordinateurs, le site se charge plus rapidement. De plus, la facilité d’utilisation des pages est un critère de classement qui augmente les positions de l’URL dans les résultats de recherche.
Facteurs comportementaux
Le temps passé par les utilisateurs sur un site est un indicateur indirect de la présence de contenu de qualité. La pagination facilite au visiteur de passer plus de temps sur le site. Une analyse des résultats de recherche a montré un lien étroit entre le comportement de l’utilisateur et les positions sur les requêtes.
Exploration et indexation
Pour que les pages de pagination apparaissent dans les résultats de recherche, vous devez connaître certaines caractéristiques dont dépend l’indexation des pages par les robots:
- Contenu unique.
Puisque Google et Yandex peuvent retirer une page de l’index si un contenu dupliqué est détecté, le propriétaire du site devrait principalement publier du contenu original sur son site. Les pages numérotées sont perçues par les robots comme des URLs distincts. Cependant, puisque les pages de pagination se ressemblent souvent, on ne doit pas oublier leur optimisation. Sinon, le robot peut les considérer comme des doublons.
- Budget d’exploration.
Googlebot est incapable de scanner toutes les pages de la ressource qu’il visite. Il a un nombre limité de pages par visite. En contournant les grands sites avec de nombreuses pages numérotées, il peut simplement manquer le quota pour scanner d’autres URLs précieuses. Dans de telles conditions, leur contenu est indexé au fil du temps.
Stratégies SEO de pagination
Il existe plusieurs approches pour dire aux robots de ne pas considérer les pages de pagination comme des doublons. Parlons de quelques-unes de ces stratégies.
Indexation de toutes les pages numérotées et de leur contenu
Dans cette approche, toutes les pages sont optimisées pour répondre aux conditions des moteurs de recherche : du contenu unique leur est ajouté, et une configuration entre les indicateurs de ressource unifiés est mise en place pour les robots d’exploration.
Particularités : les pages numérotées ainsi que les URLs qui leur sont ajoutées sont indexées et triées dans les résultats du site. Cette stratégie est pertinente à la fois pour les chaînes de pagination petite et grande.
Indexation d’une seule page récapitulative unifiée
La stratégie est basée sur la création d’une nouvelle URL qui inclut tous les résultats des catégories qui sont paginées. Les utilisateurs trouveront cette page en suivant un lien ou en cliquant sur “Voir tout”. Par conséquent, pour ajouter du contenu à l’indexation, le robot doit traiter un seul URL.
Parfois, il arrive que le moteur de recherche considère une correspondance entre les pages numérotées et “Voir tout” comme des doublons. Pour éviter cela, une balise canonique est appliquée. Sur toutes les pages numérotées, vous devriez ajouter une canonique à la page de filtre principale. Ainsi, le robot d’exploration comprendra quel contenu parmi les doublons doit être indexé en premier.
Particularités : cette méthode est pertinente pour les petites catégories, par exemple, lorsque les résultats de 3-4 pages numérotées sont affichés. Pour une grande chaîne de pagination, cette méthode n’apportera pas de résultats notables, car si beaucoup de contenu est chargé sur une page, cela affecte considérablement sa vitesse.
Fermeture des pages numérotées à l’indexation
Avec l’aide de la fermeture des pages de pagination dans le fichier robots.txt, les robots se voient interdire d’indexer toutes les pages sauf la 1ère. Cette approche permet d’économiser le budget d’exploration pour contourner d’autres URLs importantes. Aussi, avec cette méthode, vous pouvez facilement masquer les copies de page.
Particularités : cette approche convient aux grandes ressources où le contenu est affiché en étapes. L’inconvénient de la méthode est que si le robot ne trouve pas de liens sur les pages de pagination, il pourrait ne pas indexer les pages vers lesquelles elles redirigent. Cela affecte particulièrement les cas où ces URLs ne sont pas marquées sur la carte des ressources (Sitemap).
Erreurs de pagination et moyens de les détecter
Ces défauts sont identifiés à temps si vous utilisez des outils spécifiques. Discutons d’eux plus en détail.
Doublons de balises de titre et de description
Des descriptions et des titres complétés sont une étape vers l’optimisation SEO. Les données compactées sur la page web sont visibles aux utilisateurs ordinaires dans les résultats de recherche, ainsi qu’aux robots effectuant des scans. La recommandation des moteurs de recherche est de prescrire des balises de titre et de description uniques à toutes les pages du site.
Contenu dupliqué
Les robots, en comparant les pages de la ressource, remarquent des URLs avec du contenu non-unique. Lorsque Google ou Yandex détectent des doublons, ils suppriment ces URLs de l’indexation. Par conséquent, le propriétaire du site devrait suivre de près et éliminer les doublons à temps, optimisant ainsi leur site.
Mauvaise configuration des liens canoniques
Canonical est nécessaire pour rediriger les robots vers un indicateur de site unifié priorisé pour l’indexation. Sur les pages doublons/similaires, “rel=canonical” est indiqué, redirigeant vers la version canonique.
Avec une mauvaise configuration canonique, les robots peuvent ne pas prendre en compte des URLs précieuses et supprimer les pages de pagination de l’index, les considérant comme des doublons.
Outils spécialisés pour identifier les problèmes de pagination
Il existe plusieurs services conçus pour trouver les erreurs liées à l’optimisation des recherches de ressources, qui incluent également la pagination. Prenons un regard plus attentif à certains d’entre eux.
Google Search Console
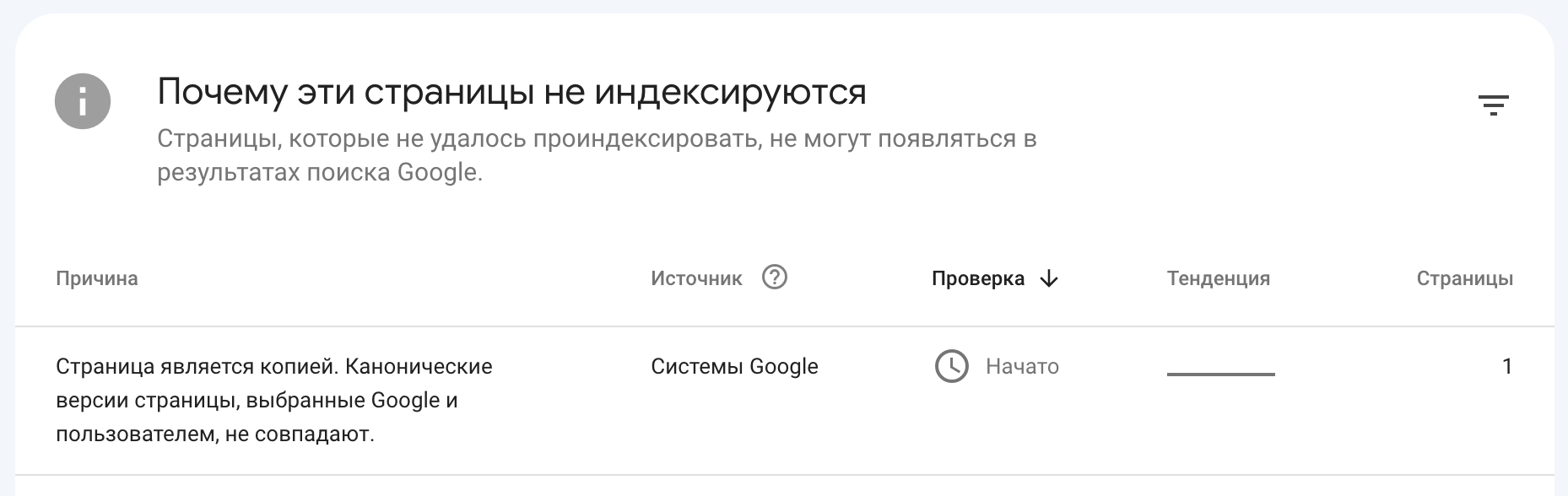
Si vous allez à la section “Indexation” puis ouvrez l’onglet “Pages”, vous pouvez voir les URLs qui ont été retirées de l’index. Vous pouvez également voir ici les pages de ressources que les moteurs de recherche ont considérées comme des doublons (ces pages seront assignées le statut “Page est une copie”).
En plus de cela, dans Google Search Console, vous pouvez voir les informations sur les problèmes de canonical.
Yandex.Webmaster
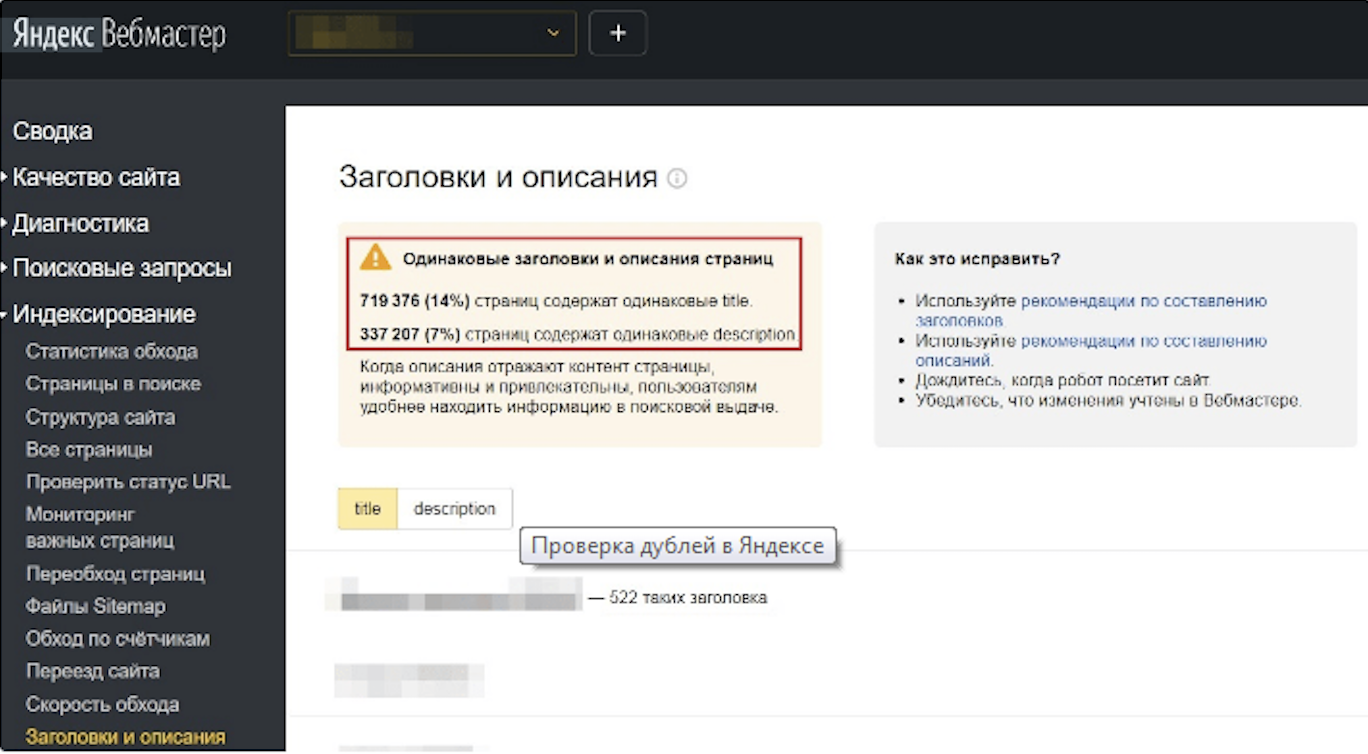
En utilisant ce service, vous pouvez voir quelles pages le robot Yandex a considérées comme des doublons, trouver des copies de titres et de descriptions. Les utilisateurs peuvent découvrir les URLs exclues de l’index en visitant la section “Indexing”. Une page web se voit assigner le statut “Duplicate” si les robots d’exploration trouvent du contenu non-unique là-bas. Les doublons de titres et de descriptions peuvent également être vus ici en cliquant sur l’onglet “Headings and Descriptions”.
Programmes pour audits détaillés
Des outils spéciaux existent qui, lorsqu’ils sont appliqués, permettent de conduire un audit détaillé du site, incluant divers paramètres techniques. Ces outils incluent Screaming Frog, qui peut vérifier un grand nombre de paramètres et fournir des moyens de résoudre les problèmes. Ce programme identifie de nombreux problèmes : doublons de titres et descriptions, problèmes de canoniques, et autres.
Configurer la pagination
Pour cela, les étapes suivantes doivent être exécutées :
Tâche 1. Indexation de toutes les pages de pagination
L’optimisation est importante pour l’indexation réussie des pages par les moteurs de recherche. Il est nécessaire que les pages aient des URLs, contenu, balises de titre, et description différents.
Pour optimiser la page de pagination, vous devez faire ce qui suit :
- Développer des pages numérotées avec des adresses originales.
Pour cela, appliquez l’imbrication des identificateurs de ressource unifiés basés sur url/n ou des paramètres de requête ?page=n. Ici n désignera le numéro de page séquentielle.
Oubliez l’ID de pagination #: Google ne peut pas reconnaître les données les suivant. Cela signifie que les robots pourraient considérer l’adresse URL comme déjà traitée et ne pas l’indexer.
- Lier les pages de pagination entre elles.
À l’aide de href, spécifiez dans le code de chacune des pages un lien vers l’URL suivante. Cela facilitera aux robots le scan du contenu partitionné. Soyez sûr d’inclure également un lien vers la 1ère page. Cela crée une indication pour les robots sur quelle page choisir durant les processus de classement.
- Créer des titres et des descriptions pour les pages.
Bien que Google permette l’utilisation de titres et de descriptions identiques durant la pagination, les titres et descriptions doivent encore être complétés pour rendre le contenu de la page unique.
- Attribuer un canonique à chaque page de pagination.
Pour cela, dans la balise, spécifiez l’attribut canonique et le lien pointant vers cette page.
Tâche 2. Indexation d’une page globale “Voir tout”.
Avec cette approche, il est possible d’optimiser efficacement “Voir tout” avec des résultats de pagination pour l’affichage dans les résultats de recherche et pour occuper des positions plus élevées. Pour cela, il est nécessaire :
- Créer une page incluant tous les résultats de pages de pagination.
Les ressources web peuvent avoir plusieurs de ces pages. Cela dépend de combien de blocs numérotés sont placés sur le site.
- Indiquer “Voir tout” comme canonique.
Assurez-vous que chaque page de pagination dans la balise écrit la propriété canonique. En considérant cela, les robots se déplaceront vers l’URL générale, qui est priorisée pour l’indexation.
- Optimiser pour que “Voir tout” se charge plus rapidement.
Plus le contenu s’affiche rapidement sur les PC, smartphones, et autres appareils, plus il y a de chance qu’un URL reçoive de meilleures positions dans les résultats. En utilisant divers services, par exemple PageSpeed Insights, vous pouvez identifier les facteurs qui ralentissent le chargement de “Voir tout”. Après avoir reçu les résultats, éliminez les causes affectant négativement les performances de la page.
Tâche 3. Interdire l’indexation des pages de pagination
Les robots d’exploration ont besoin d’un indice que l’interdiction d’indexation devrait affecter uniquement les pages de pagination. Pendant ce temps, les URLs des produits et autres résultats divisés en blocs devraient être visibles par les robots d’exploration.
Pour cela, les étapes suivantes doivent être effectuées :
- Créer une restriction sur l’indexation de toutes les pages de pagination sauf la 1ère.
Cela est réalisé en utilisant deux méthodes :
- Restreindre l’indexation avec des robots.
Sur les pages, sauf la 1ère, le bloc ajoute meta name=robots avec noindex, follow. Cette méthode permet d’interdire l’indexation de la page tout en permettant à l’utilisateur de suivre les liens placés dessus.
- Canonique à la page principale de tous les produits, représentant la plus haute valeur pour l’indexation.
Sur n’importe quelle page à laquelle la pagination s’applique, un attribut canonique est prescrit, destiné à rediriger vers la 1ère page de la séquence.
- Optimisation de la 1ère page de pagination.
Pour que la page soit indexée, on doit s’occuper des problèmes de classement : tout d’abord, on doit prêter attention au contenu et aux balises.
Conclusions
La pagination est une numérotation séquentielle des pages qui aide à améliorer la commodité de l’utilisation du site.
Il existe des méthodes spécifiques avec l’aide desquelles la configuration des pages de pagination est réalisée :
- indexation de toutes les pages de pagination;
- indexation “Voir tout”;
- restriction de l’indexation de chaque page numérotée sauf la 1ère.
Pour identifier les problèmes de pagination, appliquez les outils destinés à cet effet, tels que les sections de Yandex.Webmaster, Google Search Console, ou utilisez Screaming Frog pour l’analyse la plus approfondie du site.



