Tutto sul Tag rel=canonical e Come Applicarlo

Una panoramica completa del tag rel = “canonical” – il suo scopo, i metodi di applicazione e i problemi affrontati dagli ottimizzatori. Uno studio delle informazioni necessarie per un lavoro efficace sui tag canonici. I dati presentati di seguito sono intesi per individui che stanno appena iniziando ad esplorare questo argomento.
Rel canonical – concetti chiave e aree di applicazione
Utilizzare lo stesso contenuto su più pagine può portare a gravi penalizzazioni dai motori di ricerca. Tuttavia, in alcune situazioni, tale uso del testo può essere giustificato:
- utilizzo del sito con e senza www;
- inclusione di una pagina in due o più categorie contemporaneamente;
- filtraggio e selezione di prodotti per attributi in un catalogo.
Considerando l’ultimo esempio, spesso le pagine sono parzialmente identiche. Una potrebbe avere un filtro attivato per tipo di prodotto, e un’altra per il suo costo. Tuttavia, questo non aggiunge unicità.
Per evitare penalizzazioni, è importante determinare quale versione sarà considerata primaria o canonica, e quale sarà un duplicato. In programmazione, un tag speciale con lo stesso nome – rel = “canonical” – è stato creato per questo scopo. Aiuta a prevenire penalizzazioni dovute a contenuti duplicati.
La pagina canonica ha l’URL principale. Le altre pagine, dove viene utilizzato lo stesso contenuto, sono contrassegnate con rel = “canonical”. Questo consente al bot di riconoscere la pagina duplicata.
Perché specificare la versione primaria?
rel = “canonical” – questo è un attributo essenziale che dovrebbe essere aggiunto alle pagine duplicate. Questo requisito non solo aiuta a eliminare il rischio di penalizzazioni, ma anche a:
- ridurre le spese inutili, poiché è possibile diminuire la proporzione del budget di scansione allocato ai duplicati;
- segnalare l’URL che non solo apparirà nei risultati di ricerca, ma riceverà anche tutti i segnali;
- distribuire l’equità dei link alla pagina o al sito necessario.
È possibile studiare nel dettaglio i dati sugli URL canonici tramite due server – Yandex e Google. Le informazioni sono visualizzate nella scheda di aiuto.
Per maggiore chiarezza, è necessario esaminare i concetti con un esempio. Forniamone uno. Un sito ha una pagina che può essere accessibile attraverso tre indirizzi diversi, tra cui:
- https://my-website.com/blog/categories/144;
- https://my-website.com/blog/categories/photo;
- https://my-website.com/blog/categories/news.
Se è necessario che https://my-website.com/blog/categories/photo sia considerata la pagina canonica, non dovrebbe essere sostituita. Nel frattempo, il codice dei duplicati deve includere – . Questo passaggio comporterà che solo uno dei tre link sarà classificato nei risultati di ricerca – https://mywebsite.com/blog/categories/photo.
Indice e Pagine Non Canoniche
Gli esperti di Yandex confermano che c’è la possibilità che pagine non canoniche appaiano nei risultati di ricerca. Tuttavia, questo può avvenire solo in alcuni casi:
- alto livello di rilevanza;
- la differenza nel contenuto tra una pagina non canonica e una canonic.
Nel frattempo, Webmaster ora presenta nuove designazioni di pagine che permettono agli utenti di visualizzare il tipo desiderato. Ad esempio, se hai bisogno di studiare pagine canoniche, dovresti trovare la riga con l’etichetta canonica corrispondente nella colonna “Pagine in ricerca”.
Specialisti di Google hanno una opinione simile. Secondo loro, il sistema non è sempre in grado di riconoscere solo le pagine canoniche. Questo è perché il tag canonico non è una direttiva, ma è considerato una raccomandazione. Quindi, se il sistema riconosce un URL non canonico come più rilevante, lo mostrerà nei risultati di ricerca. Tuttavia, l’utilizzo dell’attributo canonico riduce la probabilità che il sistema riconosca l’URL della pagina sbagliata.
Nota! Nonostante queste caratteristiche, le pagine canoniche hanno priorità nei risultati di ricerca. Tuttavia, un’errata configurazione del tag può portare a problemi di indicizzazione. Pertanto, è importante comprendere le circostanze in cui l’utilizzo di tale tag è strettamente necessario.
Situazioni in cui la presenza di un tag canonico è obbligatoria
La ragione principale della presenza di un tag canonico è l’esistenza di informazioni identiche su più pagine. In altre parole, lo stesso contenuto è servito da diversi URL contemporaneamente. In tali duplicati, dovrebbe essere aggiunto un tag canonico.
Creazione di pagine duplicate
Le pagine duplicate con contenuto simile sono più comunemente trovate sulle risorse degli store online. Lì, è possibile ordinare i prodotti per un criterio specifico. Possiamo esaminare la situazione usando un negozio di mobili come esempio.
- Esempio numero uno. Se una sedia nell’assortimento è disponibile in diversi colori, puoi utilizzare un tag per evidenziare il modello (la sua pagina) che è il più popolare tra i clienti. Nel frattempo, gli utenti avranno accesso a tutti i prodotti. Solo il link al colore selezionato avrà link juice e altri segnali.
- Un’altra situazione è quando una pagina di prodotto può appartiene a diverse categorie contemporaneamente. Come risultato, appaiono più URL che si riferiscono a un singolo prodotto. In questo caso, è necessario scegliere una pagina che è molto richiesta. È questa pagina che viene aggiunta nel codice della pagina duplicata. Ciò viene fatto utilizzando il tag canonico rel = “canonical”.
Pagine di Paginazione

Quando si passa tra le pagine, vengono creati URL duplicati. Spesso si verificano errori di indicizzazione a causa di problemi nel determinare la pagina principale. Questo accade perché la scelta cade semplicemente sulla primissima pagina. Consideriamo diverse opzioni.
- Primo esempio. Se esiste un’opzione “Vedi Tutto”, allora tutte le informazioni elencate su di essa apparterranno alla pagina canonica. Per fare questo, posizionare rel = “canonical” nel codice della pagina di Paginazione.
- Per http://my-site.com/blog/categories/photo-2, è richiesto l’URL – <link rel=”canonical” href=”http://my-site.com/blog/categories/photo-2/show-all”>.
- Esempio due. Se l’opzione “Vedi Tutto” non è disponibile, allora un tipo canonico viene aggiunto a tutte le pagine.
- Per http://mysite.com/blog/categories/photo-2, il canonico sarà <link rel=”canonical” href=”http://blog/categories/photo-2″>.
- Esempio tre. Alcuni esperti ritengono che specificare un canonico a se stesso comporterà la visualizzazione di tutte le pagine di paginazione nei risultati di ricerca. Tuttavia, questo è accettabile solamente in situazioni in cui descrizioni e titoli identici su pagine con contenuti diversi sono accettabili. Si raccomanda di limitare le pagine di paginazione per questo scopo. Utilizzare follow o noindex. Disallow dovrebbe essere utilizzato nel file robots. Questo limiterà l’indicizzazione ma permetterà di seguire i link.
Tuttavia, è importante ricordare che noindex è compatibile solo con Yandex; questa opzione non è adatta per Google.
Un sito e possibili indirizzi
Gli indirizzi sono determinati in base al tipo di sito:
- https://mysite.com/;
- https://www.mysite.com/;
- http://mysite.com/;
- http://www.mysite.com/.
Tuttavia, per il motore di ricerca, questo non sarà una risorsa ma tre separate. Per correggere ciò, è necessario aggiungere un canonico. Questo aiuterà a evitare problemi con la scansione e l’indicizzazione, e anche a impostare un reindirizzamento 301 alla versione principale del sito.
URL ottimizzati per dispositivi mobili
Google ha cambiato la sua politica di ricerca facendo delle versioni mobili dei siti web il punto focale. Questo sistema è chiamato Mobile-First Indexing. Per comprendere le principali condizioni in cui l’uso del tag canonico è necessario, è essenziale studiare l’opinione dell’esperto principale di Google – John Mueller.
Se c’è una versione mobile m.nature.ru, dovresti aggiungere un tag per collegare la pagina desktop – rel = “canonical”. Per il desktop, utilizzare rel=alternate. Se tutte le condizioni sono soddisfatte correttamente, il bot riconoscerà la versione mobile come canonica o primaria. Non importa che ci sia una versione desktop nel codice. Queste impostazioni non sono soggette a modifica se applicate in Sitemap.xml.
URL di Paese
Spesso i siti web sono creati con più URL per coprire molti paesi contemporaneamente, mentre hanno lo stesso contenuto in una lingua. In tali casi, non dovresti solo selezionare una pagina canonica ma anche garantire la presenza di riferimenti a tutti i duplicati.
Tuttavia, se sono utilizzate lingue diverse su ciascun URL, dovrebbe essere utilizzato hreflang. Quindi il motore di ricerca sarà in grado di mostrare risultati separati.
Nota! Il tag hreflang dovrebbe essere utilizzato solo se è necessario specificare pagine aggiuntive con informazioni identiche. Tuttavia, sono condotte in un’altra lingua o per una regione separata.
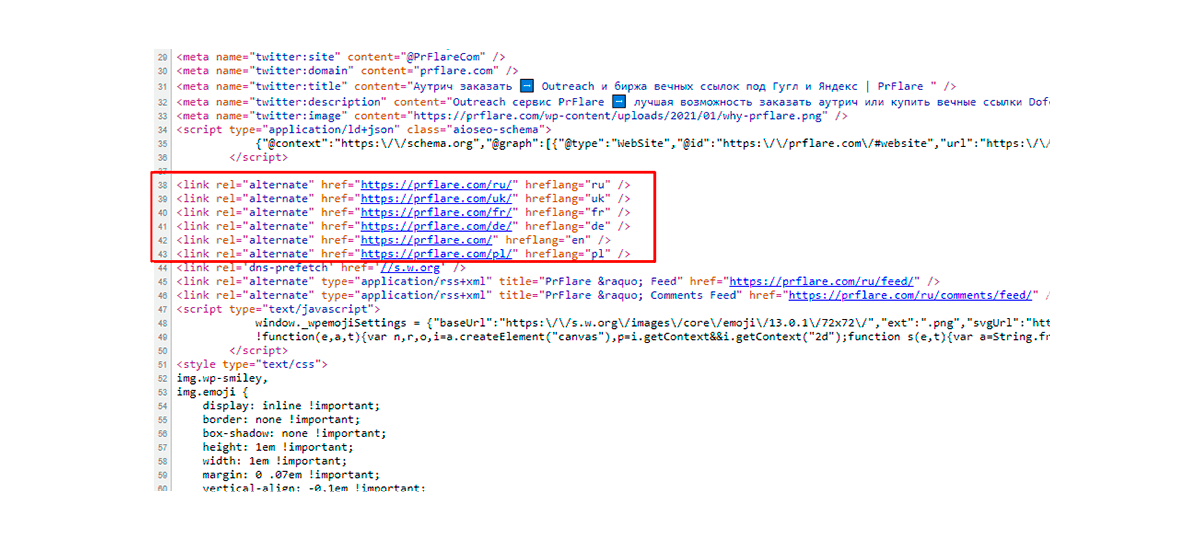
L’orientamento di Google verso i sistemi mobili ha reso obbligatorio creare corrette impostazioni hreflang. Queste includono la regola principale – tag mobili per URL mobili e tag desktop per URL desktop.
Registri
Se gli indirizzi sono contrassegnati in casi diversi, il motore di ricerca potrebbe riconoscerli come diversi. È necessario utilizzare lettere minuscole. Questo aiuterà a confermare l’identità dei link.
Modi per configurare efficacemente il canonico
Per configurare, è necessario evidenziare la pagina tra i duplicati, che sarà considerata quella principale o canonica. Viene quindi inserita in un attributo. Ad esempio, <link rel=”canonical” href=”http://mywebsite.com/blog/categories/photo-2/”>. Questo attributo è aggiunto alle pagine duplicate. Ci sono diverse opzioni, ciascuna con proprie caratteristiche e vantaggi.
Utilizzo di un plugin CMS
Per automatizzare i parametri canonici, vengono utilizzate funzionalità uniche o plugin in CMS. Per chiarezza, consideriamo alcuni esempi:
- Plugin Yoast SEO. Permette di regolare le pagine canoniche su WordPress.
- Plugin Joomla. La funzione SEF è disponibile, che aggiunge automaticamente un tag rel = “canonical”. Allo stesso tempo, è specificata la pagina principale con un URL user-friendly.
- Plugin OpenCart. Imposta gli URL SEO selezionando i prodotti in base ai parametri.
Oltre a quelli elencati, ci sono altre opzioni. In pratica, esamineremo l’opzione più comune per i CMS – WordPress.
WordPress – parametri principali di configurazione
Per aggiungere automaticamente un canonico, è necessario il plugin Yoast SEO. Tutti i parametri di impostazione sono visualizzati nella sezione “Avanzate”. Nella versione inglese – “Advanced.” L’azione principale è inserire l’URL principale della pagina. Successivamente, il plugin aggiunge nofollow o noindex alla pagina. Allo stesso tempo, il canonic è impostato per evitare ulteriori problemi nell’uscita del sito.
Ci sono altri metodi se l’opzione presentata non è adatta.
Utilizzando una pagina HTML
Questa opzione comporta l’aggiunta di un tag rel = “canonical” nella sezione <head> di una pagina duplicata. Visualmente, appare in questo modo:
- Per https://mysite.com/*utm_content, il link canonico sarà https://mysite.com/. Poi devi inserire <link rel=”canonical” href=”http://mysite.com/”> sulla risorsa https://mysite.com/*utm_content.
HTTP per l’Header
L’opzione presentata sopra non è sempre fattibile da implementare in pratica, specialmente in assenza di <head>. Pertanto, si raccomanda di ottenere l’accesso alle impostazioni del server. Dopo di ciò, puoi aggiungere a HTTP tramite PHP o .htaccess.
Se viene fatta una richiesta per un file duplicato, il server dovrebbe mostrare la versione principale.
Considera questo esempio: Le informazioni sono state compilate sotto forma di una guida, e per comodità dell’utente, possono essere scaricate dal blog. Il tipo di file è PDF. Il risultato sarà:
- Content-Type: application/pdf
- Link: <http://mysite.com/blog/canonical-tags/>; rel=”canonical”
Questo algoritmo può essere applicato quando si lavora con altre pagine.
Sitemap
Qualsiasi motore di ricerca con impostazioni predefinite analizza i link nel file XML come canonici. Alcuni servizi, come Google, rendono obbligatorio applicare solo link canonici nella sitemap. Tuttavia, questo elemento funge semplicemente da elenco di raccomandazioni. Alcuni motori di ricerca non lo tengono in considerazione.
Utilizzo di 301 (redirect)
Un altro modo per risolvere il problema è utilizzare un redirect 301. Questo è adatto quando il sito può essere accessibile tramite più indirizzi, inclusi:
- https://mysite.com/;
- https://www.mysite.com/;
- http://mysite.com/;
- http://www.mysite.com/.
La prima opzione è contrassegnata come canonica, e sono configurati i redirect per le altre.
Utilizzo di link come aggiunta
Secondo John Mueller, alcuni segnali sono necessari per determinare l’indirizzo canonico. I motori di ricerca utilizzano questi segnali. Ad esempio, se ci sono due opzioni di indirizzo https://mysite.com/ e http://www.mysite.com/, Google sceglierà il primo. Tuttavia, spesso preferisce un indirizzo più attraente. Se viene visualizzato solo un link canonico, il sistema può selezionarne un altro, ritenuto più ottimale.
Se le impostazioni sono definite in modo errato, ciò può causare seri problemi durante l’indicizzazione. In tali situazioni, gli ottimizzatori possono commettere diversi errori nel loro lavoro.
Problemi nelle impostazioni canoniche
- La regola della pagina unica
- La regola principale per una configurazione efficace è che 1 pagina corrisponde a un singolo indirizzo canonico. Se questa regola non viene seguita e ne vengono creati molti, c’è il rischio che la pagina venga ignorata dal motore di ricerca. Pertanto, è importante controllare la correttezza delle impostazioni canoniche. Per fare ciò, è necessario esaminare attentamente l’implementazione del plugin CMS.
- Una pagina – URL canonici diversi
- Nonostante l’interpretazione simile al punto precedente, l’essenza qui è diversa. Spiega che quando si usano diversi metodi per specificare il canonico, è necessario garantire che il link alla homepage sia coerente tra di loro.
- Sequenza delle pagine canoniche – impostazioni principali
- Se viene specificata una pagina principale diversa come canonica per una pagina principale, il motore di ricerca non considererà quell’indirizzo canonico. Ad esempio, per mysite.com/1, esiste un link canonico mysite.com/2, e per esso, mysite.com/3.
Posizionamento del rel = “canonical”
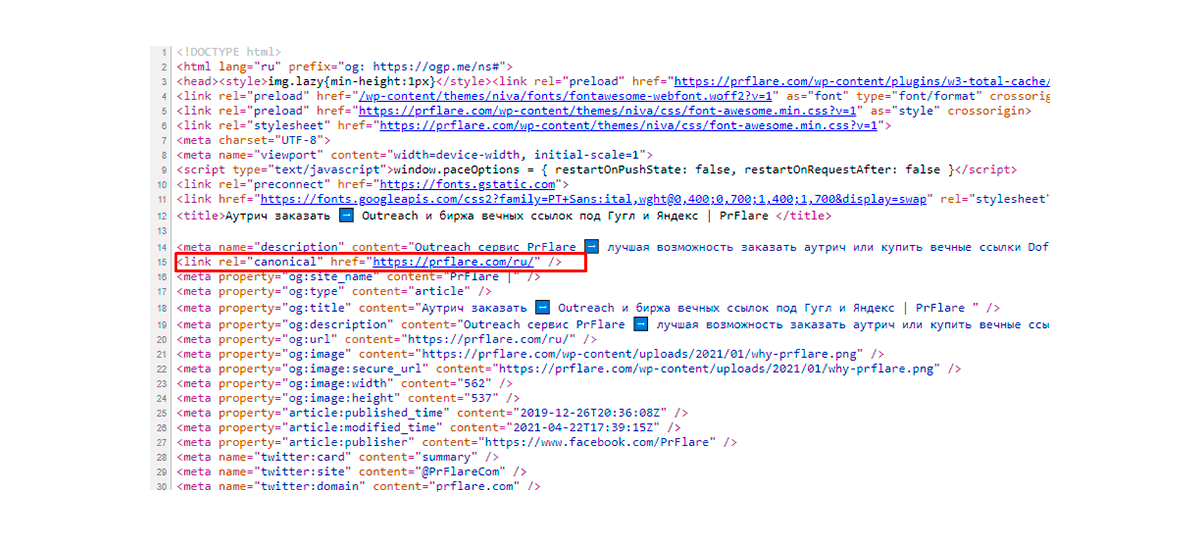
Il tag rel = “canonical” deve essere posizionato solo nella sezione head. Se viene posizionato in altre aree, il bot di ricerca non li considererà. C’è il rischio che l’intera pagina venga ignorata.
La prima pagina della paginazione – canonica
Se di tutte le pagine di paginazione solo la prima è designata come canonica, allora l’indicizzazione delle altre sarà esclusa. L’articolo presenta diverse opzioni per rettificare la situazione. Una opzione popolare è assegnare la pagina con la funzione ‘Visualizza tutto’ come canonica. La seconda opzione è specificare un canone individuale per ogni pagina.
Tuttavia, esiste la possibilità di escludere l’uso del tag canonico e cessare l’indicizzazione. Il reindirizzamento sarà ancora disponibile. Per raggiungere questo obiettivo, è necessario:
- Usare disallow per /photo.
- Applicare noindex o follow per la paginazione.
Questo metodo di configurazione viene utilizzato in situazioni in cui c’è il rischio di esiti negativi dovuti all’uso di tutte le pagine di paginazione nell’emissione con Descrizione e Titolo identici.
URL Canonico – un’alternativa al redirect 301
Anche se si può dire che la funzione di un redirect 301 e di un tag canonico sia identica, non è raccomandato interscambiarli. Il primo è mirato a indirizzare il traffico a una singola pagina, mentre il secondo nasconde dall’indicizzazione. Tuttavia, l’utilizzo di rel = “canonical” non limiterà l’ottenimento di traffico o attività.
La pagina principale agisce come canonica
Non è raccomandato configurare il link canonico in modo tale che diventi la principale per il sito. Questo porterà i bot di ricerca a ignorare tutte le altre pagine, concentrandosi sulla homepage.
Conseguenze di nascondere la pagina canonica dall’indicizzazione
Se la pagina preferita non è indicizzata, non può partecipare alla formazione dei risultati di ricerca. Lo stesso risultato si verificherà se ci sono altre ragioni per le restrizioni del motore di ricerca. In tali circostanze, sarà scelta una pagina non canonica.
Modi per controllare il canonico
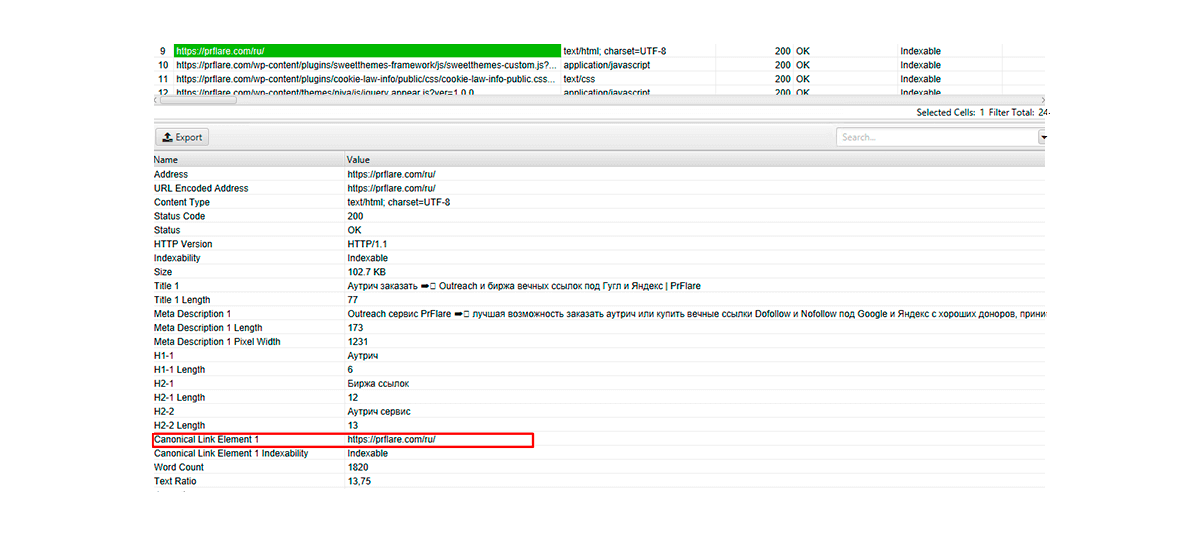
Per verificare se l’impostazione della pagina canonica è stata fatta correttamente, puoi usare il programma desktop Screaming Frog SEO Spider. Evidenzierà la pagina che Google riconosce come primaria.
Per Yandex, il percorso di verifica è diverso. Webmaster sarà adatto a tali scopi. Rimuoverà tutti i duplicati dalla ricerca, lasciando solo il link canonico. Questa informazione può essere trovata nella sezione ‘Indicizzazione’. Tutte le pagine escluse sono visualizzate nella sezione con lo stesso nome.
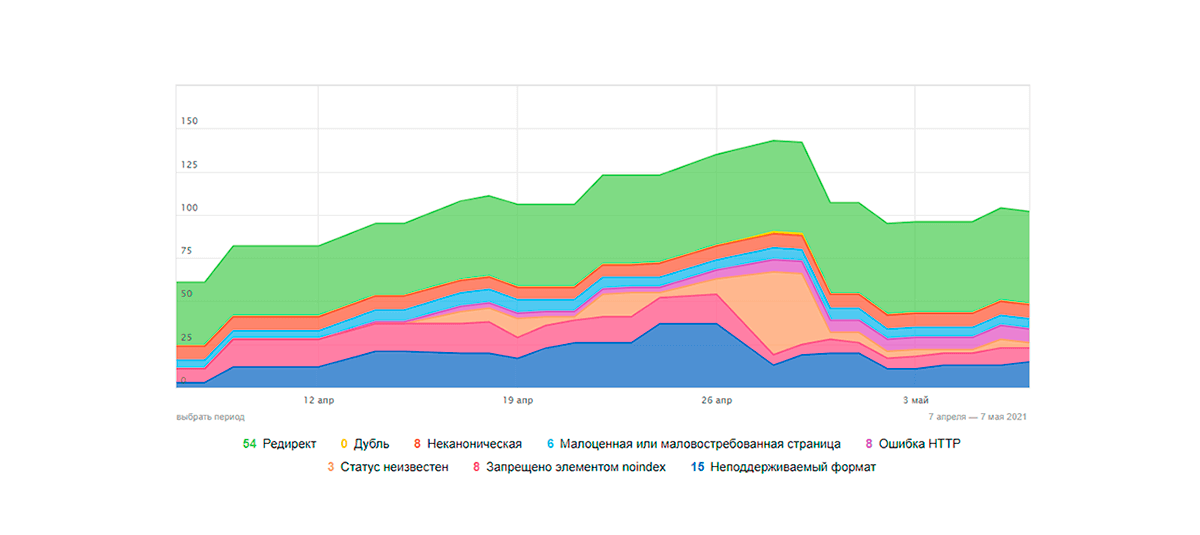
La nostra Opinione
Gli esempi sopra dimostrano l’importanza degli attributi canonici. Se qualcuno dubita ancora che gli indirizzi canonici funzionino, il caso menzionato sopra dovrebbe dissipare i loro dubbi. Se hai qualcosa da aggiungere sull’argomento discusso, ti invitiamo a condividere la tua esperienza con l’implementazione canonica in pratica nei commenti.



