Wszystko o tagu rel=canonical i jak go stosować

Kompleksowy przegląd znacznika rel = “canonical” – jego cel, metody zastosowania oraz problemy napotykane przez optymalizatorów. Studium niezbędnych informacji do skutecznej pracy nad znacznikami kanonicznymi. Dane przedstawione poniżej skierowane są do osób, które dopiero zaczynają zgłębiać ten temat.
Rel canonical – kluczowe pojęcia i obszary zastosowania
Używanie tej samej treści na wielu stronach może prowadzić do poważnych kar od wyszukiwarek. Jednak w niektórych sytuacjach takie użycie tekstu może być uzasadnione:
- używanie strony z i bez www;
- włączenie jednej strony do dwóch lub więcej kategorii jednocześnie;
- filtrowanie i wybór produktów według atrybutów w katalogu.
Rozważając ostatni przykład, najczęściej strony są częściowo identyczne. Jedna może mieć aktywowany filtr według rodzaju produktu, a inna według jego kosztu. Jednak to nie dodaje unikalności.
Aby uniknąć kar, ważne jest ustalenie, która wersja zostanie uznana za nadrzędną, czyli kanoniczną, a która będzie dublatem. W programowaniu utworzono specjalny tag o tej samej nazwie – rel = “canonical” – do tego celu. Pomaga on uniknąć kar wynikających z duplikacji treści.
Strona kanoniczna ma główny URL. Inne strony, gdzie używana jest ta sama treść, są oznaczone rel = “canonical”. Dzięki temu bot może rozpoznać stronę-duplikat.
Dlaczego warto określić wersję główną?
rel = “canonical” – to niezbędny atrybut, który powinien być dodawany do stron-duplikatów. To wymaganie nie tylko pomaga eliminować ryzyko kar, ale także pomaga w:
- zmniejszeniu niepotrzebnych wydatków, ponieważ można obniżyć proporcję budżetu skanowania przydzielonego na duplikaty;
- sygnalizowaniu URL-a, który nie tylko pojawi się w wynikach wyszukiwania, ale także otrzyma wszystkie sygnały;
- dystrybucji wartości linków do koniecznej strony lub witryny.
Można szczegółowo zapoznać się z danymi o URL-ach kanonicznych poprzez dwa serwery – Yandex i Google. Informacje wyświetlane są w zakładce pomocy.
Dla większej przejrzystości należy przeanalizować pojęcia na przykładzie. Podajmy jeden. Strona ma stronę, która może być dostępna przez trzy różne adresy, w tym:
- https://mojastrona.com/blog/categories/144;
- https://mojastrona.com/blog/categories/photo;
- https://mojastrona.com/blog/categories/news.
Jeśli konieczne jest, aby https://mojastrona.com/blog/categories/photo była uznawana za stronę kanoniczną, nie powinna być zastępowana. Tymczasem w kodzie duplikatów należy zawrzeć – . Ten krok spowoduje, że w wynikach wyszukiwania zostanie oceniony tylko jeden z trzech linków – https://mojastrona.com/blog/categories/photo.
Indeksowanie i strony niekanoniczne
Eksperci Yandex potwierdzają, że istnieje szansa, iż strony niekanoniczne pojawią się w wynikach wyszukiwania. Jednak może się to zdarzyć tylko w kilku przypadkach:
- wysoki poziom istotności;
- różnica w treści między stroną niekanoniczną a kanoniczną.
Tymczasem w Narzędziach dla Webmasterów pojawiają się nowe oznaczenia stron, które pozwalają użytkownikom na przeglądanie pożądanego rodzaju. Na przykład, jeśli potrzebujesz zbadać strony kanoniczne, powinieneś znaleźć linię z odpowiadającą jej etykietą kanoniczną w kolumnie „Strony w wyszukiwarce”.
Specjaliści Google mają podobne zdanie. Według nich system nie zawsze jest w stanie rozpoznać tylko strony kanoniczne. Dzieje się tak, ponieważ znacznik kanoniczny nie jest dyrektywą, ale jest uważany za zalecenie. Dlatego jeśli system rozpozna niekanoniczny URL jako bardziej istotny, wyświetli go w wynikach wyszukiwania. Jednak użycie atrybutu kanonicznego zmniejsza prawdopodobieństwo, że system rozpozna niewłaściwy URL strony.
Uwaga! Mimo tych cech, strony kanoniczne mają priorytet w wynikach wyszukiwania. Jednak niepoprawna konfiguracja tagu może prowadzić do problemów z indeksowaniem. Dlatego ważne jest zrozumienie okoliczności, w jakich konieczne jest stosowanie takiego tagu.
Sytuacje, w których obecność tagu kanonicznego jest obowiązkowa
Głównym powodem obecności tagu kanonicznego jest istnienie identycznych informacji na wielu stronach. Innymi słowy, ta sama treść jest udostępniana przez kilka URLi jednocześnie. W przypadku takich duplikatów należy dodać tag kanoniczny.
Tworzenie duplikatów stron
Duplikaty stron z podobną treścią najczęściej znajdują się na zasobach sklepów internetowych. Tam można sortować produkty według określonego kryterium. Możemy przeanalizować tę sytuację na przykładzie sklepu meblowego.
- Przykład numer jeden. Jeśli krzesło w asortymencie jest dostępne w kilku kolorach, można użyć tagu, aby wyróżnić model (jego stronę), który jest najpopularniejszy wśród klientów. Tymczasem użytkownicy będą mieli dostęp do wszystkich produktów. Tylko link do wybranego koloru będzie miał siłę linków i inne sygnały.
- Inna sytuacja to taka, że strona produktu może należeć do kilku kategorii jednocześnie. W rezultacie pojawia się wiele URLi odnoszących się do jednego produktu. W tym przypadku konieczne jest wybranie jednej strony, która jest najczęściej poszukiwana. To ta strona jest dodawana do kodu duplikatów. Dokonuje się tego przy pomocy kanonicznego tagu rel = “canonical”.
Strony paginacji

Przy przełączaniu stron powstają duplikaty URLi. Błędy indeksowania często występują z powodu problemów w określaniu strony głównej. Dzieje się tak, ponieważ wybór po prostu pada na pierwszą stronę. Rozważmy kilka opcji.
- Pierwszy przykład. Jeśli istnieje opcja “Pokaż wszystko”, to wszystkie informacje na niej wymienione będą należeć do strony kanonicznej. Aby to zrobić, umieść rel = “canonical” w kodzie strony Paginacji.
- Dla http://mojastrona.com/blog/categories/photo-2, wymagany jest URL – <link rel=”canonical” href=”http://mojastrona.com/blog/categories/photo-2/show-all”>.
- Drugi przykład. Jeśli opcja „Pokaż wszystko” nie jest dostępna, to kanoniczny typ jest dodawany do wszystkich stron.
- Dla http://mojastrona.com/blog/categories/photo-2, kanoniczny będzie działał <link rel=”canonical” href=”http://blog/categories/photo-2″>.
- Trzeci przykład. Niektórzy eksperci uważają, że określenie kanoniku dla samego siebie spowoduje wyświetlenie wszystkich stron paginacji w wynikach wyszukiwania. Jednak jest to dopuszczalne tylko w sytuacjach, gdy identyczne opisy i tytuły na stronach z różną treścią są akceptowane. Zaleca się ograniczenie stron paginacji w takim celu. Używaj follow lub noindex. Disallow powinien być używany w pliku robots. To ograniczy indeksowanie, ale pozwoli na śledzenie linków.
Jednak ważne jest, aby pamiętać, że noindex jest kompatybilny tylko z Yandexem; ta opcja nie jest odpowiednia dla Google.
Jedna strona i możliwe adresy
Adresy są określane na podstawie typu strony:
- https://mojastrona.com/;
- https://www.mojastrona.com/;
- http://mojastrona.com/;
- http://www.mojastrona.com/.
Jednak dla wyszukiwarki to nie będzie jeden zasób, a trzy osobne. Aby to poprawić, musisz dodać kanoniczny. To pomoże uniknąć problemów ze skanowaniem i indeksowaniem, a także ustawić przekierowanie 301 na główną wersję strony.
Użycie mobilnego URL
Google zmienił swoją politykę wyszukiwania, czyniąc mobilne wersje stron internetowych głównym celem. System ten nazywa się Mobilne Indeksowanie. Żeby zrozumieć główne warunki, w których potrzebne jest użycie tagu kanonicznego, ważne jest zapoznanie się z opinią czołowego eksperta Google – Johna Muellera.
Jeśli istnieje mobilna wersja m.nature.ru, powinieneś dodać tag w celu połączenia z wersją desktopową – rel = “canonical”. Dla wersji desktop użyj rel=alternate. Jeśli wszystkie warunki są prawidłowo spełnione, bot uzna wersję mobilną za kanoniczną lub główną. Nie ma znaczenia, że w kodzie znajduje się wersja desktop. Te ustawienia nie są podlegające zmianom, jeśli są stosowane w pliku Sitemap.xml.
Adres URL w zależności od kraju
Często strony internetowe są tworzone z wieloma URLami, aby objąć wiele krajów jednocześnie, przy czym mają tę samą treść w jednym języku. W takich przypadkach powinieneś nie tylko wybrać stronę kanoniczną, ale także zapewnić obecność odniesień do wszystkich duplikatów.
Jednak jeśli na każdym adresie URL są używane różne języki, powinno się używać hreflanga. Wówczas wyszukiwarka będzie w stanie pokazać oddzielne wyniki.
Uwaga! Tag hreflang powinien być używany tylko wtedy, gdy konieczne jest określenie dodatkowych stron z identyczną informacją. Jednak są one prowadzone w innym języku lub dla oddzielnego regionu.
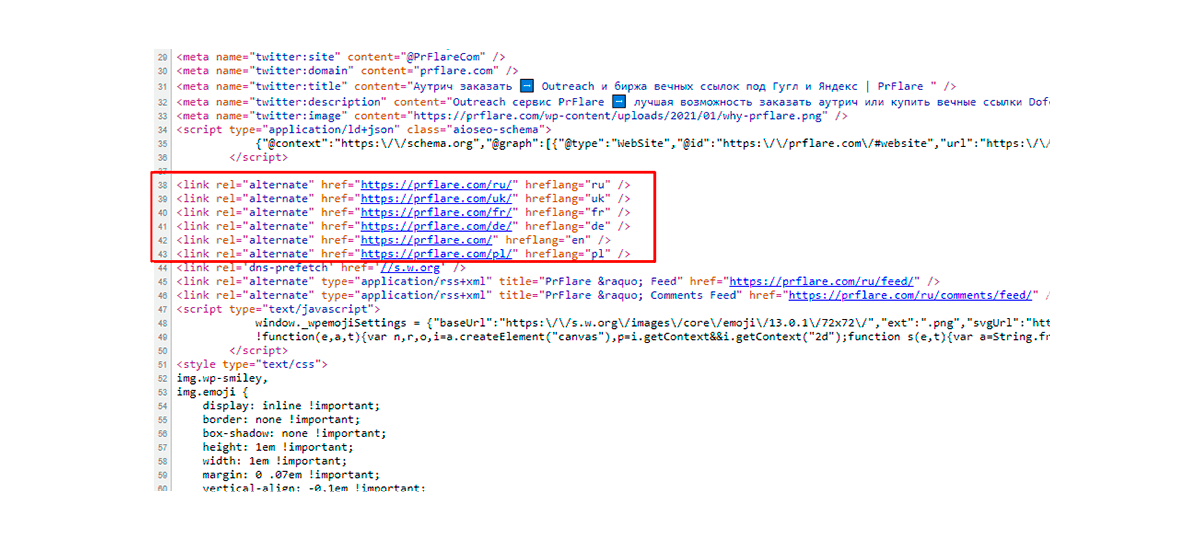
Przejście Google na systemy zorientowane na urządzenia mobilne sprawiło, że stworzenie poprawnych ustawień hreflang stało się obowiązkowe. Obejmuje to główną zasadę – tagi mobilne dla mobilnych URLi oraz desktopowe tagi dla desktopowych URLi.
Rejestry
Jeśli adresy są oznaczone w różnych przypadkach, wyszukiwarka może je rozpoznać jako różne. Należy używać małych liter. To pomoże potwierdzić tożsamość linków.
Sposoby efektywnego ustawienia kanonika
Aby skonfigurować, należy wyróżnić stronę wśród duplikatów, która będzie uznawana za główną lub kanoniczną. Następnie jest wprowadzana do atrybutu. Na przykład, <link rel=”canonical” href=”http://mojastrona.com/blog/categories/photo-2/”>. Ten atrybut jest dodawany do stron duplikatów. Istnieje kilka opcji, z których każda ma swoje cechy i zalety.
Użycie pluginu CMS
Do automatyzacji parametrów kanonicznych używany jest unikalny zestaw funkcji lub pluginy w CMS. Dla przejrzystości, rozważmy kilka przykładów:
- Plugin Yoast SEO. Umożliwia dostosowanie stron kanonicznych na WordPress.
- Plugin Joomla. Dostępna jest funkcja SEF, która automatycznie dodaje znacznik rel = “canonical”. Jednocześnie, określana jest strona główna z przyjaznym URLem.
- Plugin OpenCart. Ustala SEO URL, wybierając produkty według parametrów.
Oprócz wymienionych, istnieją inne opcje. W praktyce przeanalizujemy najczęściej występującą opcję dla CMS – WordPress.
WordPress – główne parametry konfiguracji
Aby automatycznie dodać kanoniczny, wymagany jest plugin Yoast SEO. Wszystkie parametry ustawień wyświetlane są w sekcji “Zaawansowane”. W wersji angielskiej – „Advanced”. Główna czynność to wprowadzenie głównego URL strony. Po tym plugin dodaje nofollow lub noindex do strony. Jednocześnie ustawia się kanoniczny, aby unikać dalszych problemów z wynikami strony.
Istnieją inne metody, jeśli zaprezentowana opcja nie jest odpowiednia.
Użycie strony HTML
Ta opcja polega na dodaniu tagu rel = “canonical” do sekcji <head> strony duplikatu. Wizualnie wygląda to tak:
- Dla https://mojastrona.com/*utm_content, kanonicznym linkiem będzie https://mojastrona.com/. Następnie należy wprowadzić <link rel=”canonical” href=”http://mojastrona.com/”> na zasobie https://mojastrona.com/*utm_content.
HTTP dla nagłówków
Opcja przedstawiona powyżej nie zawsze jest wykonalna w praktyce, szczególnie przy braku <head>. Dlatego zaleca się uzyskanie dostępu do ustawień serwera. Następnie można dodać do HTTP przez PHP lub .htaccess.
Jeśli zostanie złożone żądanie pliku duplikatu, serwer powinien wyświetlić główną wersję.
Rozważmy ten przykład: Informacje zostały zebrane w formie przewodnika, i dla wygody użytkownika można je pobrać z bloga. Typ pliku to PDF. Wynik będzie:
- Content-Type: application/pdf
- Link: <http://mojastrona.com/blog/canonical-tags/>; rel=”canonical”
Ten algorytm może być stosowany przy pracy z innymi stronami.
Mapa strony
Każda wyszukiwarka z domyślnymi ustawieniami analizuje linki w pliku XML jako kanoniczne. Niektóre usługi, jak Google, czynią obowiązkowym stosowanie tylko kanonicznych linków w mapie strony. Jednak ten element działa jedynie jako lista zaleceń. Niektóre wyszukiwarki nie biorą tego pod uwagę.
Użycie 301 (przekierowanie)
Inny sposób rozwiązania problemu to użycie przekierowania 301. Jest to odpowiednie, gdy stronę można uzyskać przez wiele adresów, w tym:
- https://mojastrona.com/;
- https://www.mojastrona.com/;
- http://mojastrona.com/;
- http://www.mojastrona.com/.
Pierwsza opcja jest oznaczona jako kanoniczna, a dla pozostałych konfiguruje się przekierowania.
Używanie linków jako dodatku
Według Johna Muellera, do określenia kanonicznego adresu potrzebne są określone sygnały. Wyszukiwarki używają tych sygnałów. Na przykład, jeśli istnieją dwie opcje adresu https://mojastrona.com/ i http://www.mojastrona.com/, Google wybierze pierwszą. Jednak często woli bardziej atrakcyjny adres. Jeśli wyświetlany jest tylko jeden kanoniczny link, system może wybrać inny, uznany za bardziej optymalny.
Jeśli ustawienia są zdefiniowane niepoprawnie, spowoduje to poważne problemy podczas indeksowania. W takich sytuacjach optymalizatorzy mogą popełniać kilka błędów w swojej pracy.
Problemy w ustawieniach kanonicznych
- Zasada jednej strony
- Główna zasada efektywnego ustawienia to 1 strona odpowiadająca jednemu kanonicznemu adresowi. Jeśli ta zasada nie jest przestrzegana i tworzone są wiele, istnieje ryzyko, że strona zostanie zignorowana przez wyszukiwarkę. Dlatego ważne jest sprawdzenie poprawności ustawień kanonicznych. W tym celu należy dokładnie zbadać implementację pluginu w CMS.
- Jedna strona – różne kanoniczne URLe
- Mimo podobnego interpretacji do poprzedniego punktu, tutaj sedno jest inne. Wyjaśnia, że przy użyciu kilku metod określania kanonicznego, należy zapewnić, aby link do strony głównej był spójny wśród nich.
- Kolejność stron kanonicznych – główne ustawienia
- Jeśli inna strona główna jest wskazana jako kanoniczna dla jednej głównej strony, wyszukiwarka nie uwzględni tego adresu kanonicznego. Na przykład, dla mojastrona.com/1, istnieje kanoniczny link mojastrona.com/2, a dla niego mojastrona.com/3.
Umiejscowienie rel = “canonical”
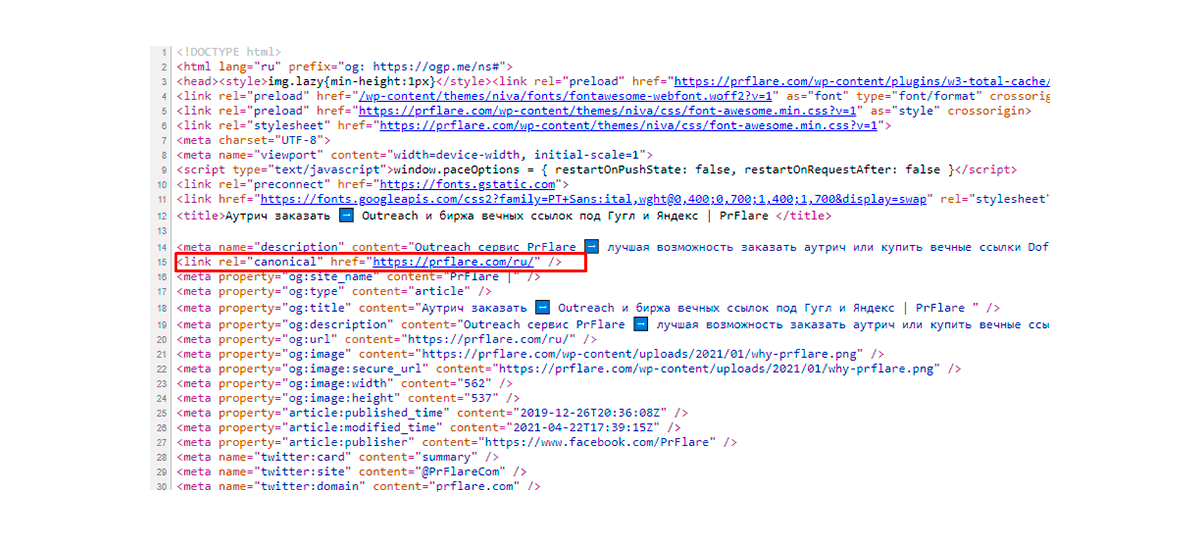
Znacznik rel = “canonical” powinien być umieszczany tylko w sekcji head. Jeśli zostanie umieszczony w innych obszarach, bot wyszukiwania go nie uwzględni. Istnieje ryzyko, że cała strona zostanie zignorowana.
Pierwsza strona paginacji – kanoniczna
Jeśli ze wszystkich stron paginacji tylko pierwsza jest oznaczona jako kanoniczna, to indeksowanie pozostałych zostanie wykluczone. Artykuł przedstawia kilka opcji poprawiających sytuację. Popularną opcją jest przypisanie strony z funkcją ‘Pokaż wszystko’ jako kanonicznej. Drugą opcją jest określenie indywidualnego kanonicznego dla każdej strony.
Jednak istnieje możliwość wykluczenia użycia tagu kanonicznego i zaprzestania indeksowania. Przekierowanie nadal będzie dostępne. Aby to osiągnąć, musisz:
- Użyj disallow dla /photo.
- Zastosuj noindex lub follow dla paginacji.
Ten sposób konfiguracji stosowany jest w sytuacjach, gdy istnieje ryzyko negatywnych rezultatów z powodu użycia wszystkich stron paginacji w emisji z identycznymi Opisami i Tytułami.
URL kanoniczny – alternatywa dla przekierowania 301
Pomimo że funkcja przekierowania 301 i znacznik kanoniczny można powiedzieć, że są identyczne, nie jest zalecane zamienianie ich miejscami. Pierwsze skupia się na kierowaniu ruchu na jedną stronę, podczas gdy drugie ukrywa przed indeksowaniem. Jednak użycie rel = “canonical” nie ograniczy uzyskiwania ruchu lub aktywności.
Strona główna działa jako kanoniczna
Nie zaleca się konfigurowania kanonicznego linku w taki sposób, że staje się głównym dla strony. To spowoduje, że boty wyszukiwania zignorują wszystkie inne strony, skupiając się na stronie głównej.
Konsekwencje ukrycia strony kanonicznej przed indeksowaniem
Jeśli preferowana strona nie jest indeksowana, nie może uczestniczyć w tworzeniu wyników wyszukiwania. To samo odnosi się do sytuacji, gdy istnieją inne przyczyny ograniczeń ze strony wyszukiwarki. W takich okolicznościach zostanie wybrana strona niekanoniczna.
Sposoby sprawdzenia kanonika
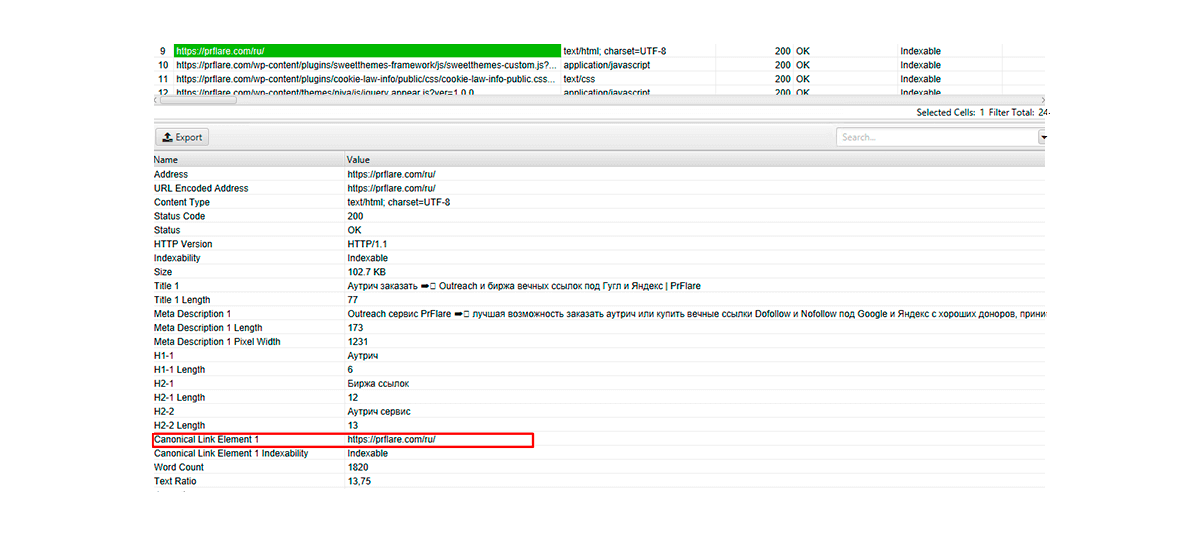
Aby sprawdzić, czy konfiguracja strony kanonicznej została wykonana poprawnie, można użyć programu desktopowego Screaming Frog SEO Spider. Podkreśli on stronę, którą Google rozpoznaje jako główną.
Dla Yandex ścieżka weryfikacji jest inna. Webmaster będzie odpowiedni dla takich celów. Usunie wszystkie duplikaty z wyszukiwania, pozostawiając tylko kanoniczny link. Informacje te można znaleźć w sekcji ‘Indeksowanie’. Wszystkie wykluczone strony są wyświetlane w sekcji o tej samej nazwie.
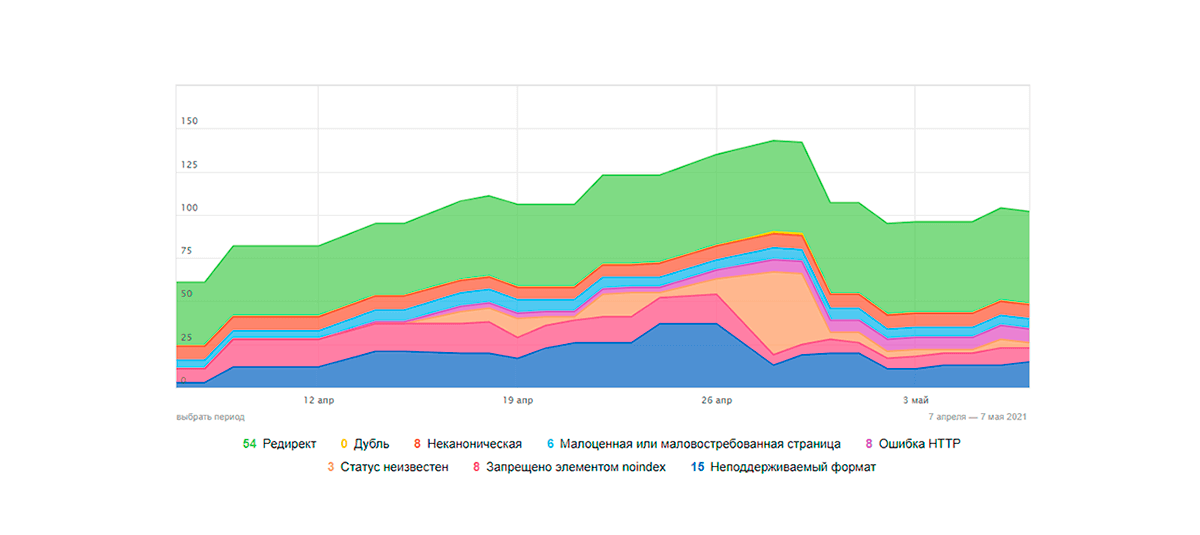
Nasza opinia
Podane powyżej przykłady pokazują znaczenie atrybutów kanonicznych. Jeśli ktoś nadal wątpi, czy kanoniczne adresy faktycznie działają, przypadek wspomniany wyżej powinien rozwiać wszelkie wątpliwości. Jeśli masz coś do dodania na temat omawiany, zapraszamy do podzielenia się swoim doświadczeniem z implementacją kanonicznych w praktyce w komentarzach.



