Усе про тег rel canonical і способи його застосування

Повноцінний обсяг інформації про rel = “canonical” – його призначення, способи застосування та дефекти, що виникають у роботі оптимізаторів. Вивчення відомостей, необхідних для ефективної роботи над канонічними тегами. Наведені нижче дані призначені для людей, які тільки починають осягати цю тему.
Rel canonical – головні поняття та сфери застосування
Використання одного контенту на кількох сторінках призведе до серйозних санкцій від пошукових систем. Однак у деяких ситуаціях таке застосування тексту може бути виправданим:
- використання сайту з www і без;
- входження 1 сторінки одночасно у дві та більше категорії;
- фільтрація і підбір продукції за ознаками в каталозі.
Якщо розглядати останній приклад, то найчастіше сторінки ідентичні частково. На одній може бути активований фільтр за типом виробів, а на другій за його вартістю. Однак унікальності це не додасть.
Щоб не отримати санкції, варто з’ясувати, який варіант вважатиметься основним або канонічним, а який дублюючим. У програмуванні на цей випадок було створено спеціальний однойменний тег – rel = “canonical”. Він допомагає виключити санкції через використання однієї інформації.
Канонічна сторінка має головний URL. На інші, де використовується такий самий контент, приписують rel = “canonical”. Це дасть змогу боту розпізнати повторювану сторінку.
Яка необхідність у зазначенні основної версії?
rel = “canonical” – це необхідний атрибут, який слід додавати на сторінки дублікати. Така вимога не тільки посприяє позбавленню від ризиків санкцій, а й допоможе:
- усунути зайві витрати, ви зможете знизити частку краулінгового бюджету, що припадає на дублікати;
- відзначити URL, який не тільки буде відображатися в пошуку, а й отримає весь обсяг сигналів;
- розподілити кількість посилань на необхідну сторінку або сайт.
Більш детально вивчити дані про URL канонічного типу можна завдяки двом серверам – Яндекс і Google. Відомості відображаються у вкладці довідка.
Для більшої ясності необхідно вивчити поняття на прикладі. Наведемо його. У сайту є сторінка, доступ до якої можна отримати одразу за трьома адресами, включно з:
- https://сайт.ком/блог/категорії/144;
- https://сайт.ком/блог/категорії/фото;
- https://сайт.ком/блог/категорії/новини.
Якщо необхідно, щоб https://сайт.ком/блог/категорії/фото вважалася канонічною сторінкою, її замінювати не треба. При цьому в код дублікатів необхідно буде додати – <link rel=”canonical” href=”https://сайт.ком/блог/категорії/фото”/>. Такий крок призведе до того, що з трьох посилань ранжуватися у видачі ранжуватиметься тільки одне – https://сайт.ком/блог/категорії/фото.
Індекс і неканонічні сторінки
Фахівці Яндекса підтверджують, що є ймовірність, що неканонічні сторінки відображатимуться у видачі. Однак статися таке може тільки в кількох випадках:
- високий рівень релевантності;
- відмінність контенту неканонічної сторінки від канонічної сторінки.
При цьому у Вебмайстері з’явилися нові позначення сторінок, що дають змогу переглянути вид, який цікавить. Наприклад, якщо необхідно вивчити канонічні сторінки, то в графі “Сторінки в пошуку” слід відшукати рядок із відповідною однойменною позначкою.
Такої думки дотримуються фахівці Google. За їхніми словами система не здатна завжди визнавати тільки канонічно сторінки. Це пояснюється тим фактором, що canonical не належить до групи закликів. Він розглядається у вигляді рекомендації. Тому, якщо система розпізнає неканонічний URL більш релевантним, то він і буде відображатися в пошуку. Однак використання спеціального атрибута знижує ймовірність того, що система розпізнає не той URL сторінки.
Зверніть увагу! Попри такі особливості першість у пошуку належить саме канонічним сторінкам. Однак неправильне регулювання тега може призвести до проблем під час індексації. Тому важливо вивчити моменти, за яких використання такого тега суворо необхідне.
Ситуації, в яких обов’язкова наявність канонічного тега
Головна причина наявності тега canonical – присутність ідентичної інформації на кількох сторінках. Іншими словами, відбувається одночасне обслуговування одного контенту кількома URL. При цьому в подібні дублі слід додавати канонічний тег.
Створення дублів сторінок
Найчастіше дублюючі сторінки, що мають однотипний зміст, зустрічаються на ресурсах онлайн-магазинів. Там є можливість сортування продукції за певним критерієм. Можна розглянути ситуацію на прикладі магазину меблів.
- Приклад номер один. Якщо в асортименті є крісло кількох кольорів, то можна за допомогою тега виділити ту модель (її сторінку), яка користується найбільшим попитом серед покупців. При цьому доступ для користувачів буде відкритий на всі вироби. Тільки посилання на обраний колір матиме посилальну вагу та інші сигнали.
- Ще одна ситуація, коли сторінка товару може належати відразу до кількох категорій. У результаті з’являється безліч URL, що належать до одного товару. У цьому разі необхідно вибрати одну сторінку, що користується великим попитом. Саме вона додається до коду, що належить дублюючій сторінці. Для цього вдаються до канонічного тегу rel = “canonical”.
Сторінки пагінації

Під час перемикання сторінок створюються дублюючі URL. Часто виникають помилки індексації через проблеми у визначенні головної сторінки. Це відбувається через те, що вибір падає просто на першу ж сторінку. Розглянемо кілька варіантів.
-
- Приклад перший. Якщо існує пункт “Переглянути все”, то вся інформація, зазначена на ній, належатиме canonical сторінці. Для цього варто помістити rel = “canonical” у код сторінки Pagination. Для http://сайт.ком/блог/категорії/фото-2 обов’язковий URL – <link rel=”canonical” href=”http://сайт.ком/блог/категорії/фото-2/show-all”>..
- Приклад другий. Якщо такого пункту, як “Переглянути все” немає, то всім сторінкам додається канонічний тип. Для сайт.ком/блог/категорії/фото-2 канонічна буде – <link rel=”canonical” href=”http://сайт.ком/блог/категорії/фото-2″>.
- Приклад третій. Деякі фахівці дотримуються думки, що вказівка canonical на саму себе, стане причиною того, що в результаті пошуку будуть відображатися всі сторінки пагінації. Однак такий варіант прийнятний тільки за тих обставин, коли прийнятні однакові описи і заголовки на сторінках з різним контентом. Для цього рекомендується здійснити закриття сторінки пагінації. Варто скористатися follow або noindex. Використовувати слід disallow у файлі robots. Це обмежить індексацію, але дозволить перехід за посиланнями.
Однак важливо пам’ятати, що noindex поєднується тільки з Яндексом, для Google цей варіант не підходить.
Один сайт і можливі адреси
Виходячи з типу сайту визначаються його адреси:
-
-
- https://сайт.ком/;
- https://www.сайт.ком/;
- http://сайт.ком/;
- http://www.сайт.ком/.
-
Однак для пошукової системи це буде не один ресурс, а три окремих. Щоб виправити це, необхідно додати canonical. Це дасть змогу уникнути неполадок у скануванні та індексації, а також поставити 301 редирект на основну версію сайту.
URL оптимізований під мобільні пристрої
Google змінив свою політику пошуку зробивши головним орієнтиром – мобільні версії Інтернет-ресурсів. Така система називається Mobile-First Indexing. Щоб розібратися в основних умовах, де необхідне використання канонічного тега, необхідно вивчити думку провідного фахівця компанії Google – Джона Мюллера.
Якщо існує мобільна версія m.nature.ru, то варто додати тег, що переносить на десктопну сторінку, – rel = “canonical”. Для десктопної застосовують rel=alternate. Якщо всі умови було виконано правильно, то бот розпізнаватиме версію для мобільних пристроїв як канонічну або основну. При цьому не важливо, що в коді є десктопна. Зміні не підлягають такі налаштування, якщо їх застосовують у Sitemap.xml.
URL країни
Нерідко сайти створюються з кількома URL, щоб охопити відразу багато країн. При цьому вони мають один контент однією мовою. У такому разі слід не просто вибрати канонічну сторінку, а й забезпечити наявність відсилань до всіх дублів.
Однак, якщо на кожному URL використовуються різні мови, то застосовувати варто hreflang. Тоді пошукова система зможе показати окремі результати.
Зверніть увагу! Такий тег, як hreflang, варто застосовувати тільки в тому разі, якщо необхідно вказати додаткові сторінки з ідентичною інформацією. Однак вони ведуться іншою мовою або для окремої області.
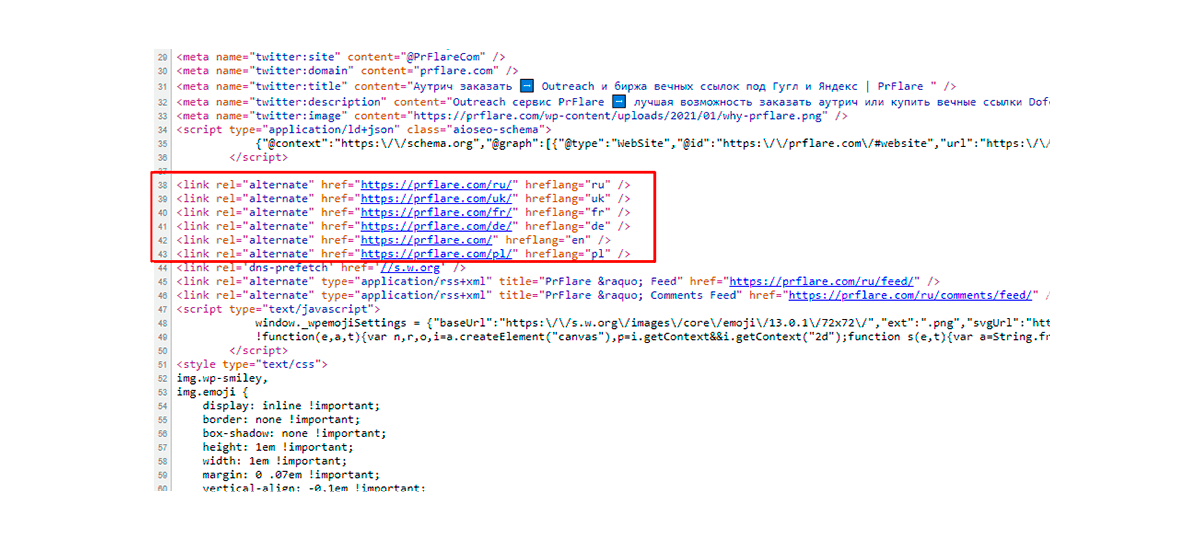
Перемикання системи Google на орієнтованість для мобільних пристроїв зробило обов’язковим створення правильних налаштувань hreflang. Вони включають в себе головне правило – мобільні теги на мобільні URL, а десктопні на десктопні URL.
Регістри
Якщо адреси зазначені в різних регістрах, то пошукова система може їх розпізнати у вигляді різних. Необхідно використовувати нижній тип регістру. Це допоможе підтвердити ідентичність посилань.
Способи ефективного налаштування canonical
Щоб зробити налаштування, необхідно серед дублів виділити сторінку, яка вважатиметься основною або канонічною. Вона в майбутньому вписується в атрибут. Наприклад, . Цей атрибут додається до сторінок, що дублюють. Існує кілька варіантів, кожен має свої особливості та переваги.
Використовуючи плагін CMS
Для автоматизації параметрів canonical використовується унікальний функціонал або плагіни в CMS. Для наочності розглянемо кілька прикладів:
-
-
- Плагін Yoast SEO. Дає змогу здійснити регулювання канонічних сторінок на WordPress.
- Плагін Joomla. Доступна функція SEF, яка автоматично додає тег rel = “canonical”. При цьому вказується основна сторінка з URL-адресою, зрозумілою для користувача.
- Плагін OpenCart. За допомогою відбору продукції за параметрами задає SEO URL.
-
Крім перерахованих є й інші варіанти. На практиці вивчимо найпоширеніший варіант для CMS – WordPress.
WordPress – основні параметри налаштування
Для автоматичного додавання canonical необхідний плагін Yoast SEO. Усі параметри налаштувань відображаються в розділі “Додатково”. В англомовному варіанті – “Advanced”. Головна дія – введення основного URL сторінки. Поле цього плагін додає на сторінку nofollow або noindex. При цьому встановлюється canonical, щоб унеможливити подальші проблеми під час видачі сайту.
Є й інші способи, якщо представлений варіант не підходить.
Використання HTML-сторінки
Такий варіант передбачає додавання в секціюсторінки, що дублює, тег rel = “canonical”. Наочно це має такий вигляд:
Для https://сайт.ком/*utm_content канонічним посиланням буде https://сайт.ком/. Тоді необхідно вписати на ресурс https://сайт.ком/*utm_content.
HTTP для заголовка
Представлений вище варіант застосувати на практиці виходить не завжди. Особливо за умови відсутності < head >. Тому рекомендується отримати доступ до сервісного налаштування. Після цього можна буде додати в HTTP PHP або.htaccess.
Якщо виконано запит файлу дубліката, то сервер має відобразити основний варіант.
Розглянемо такий приклад: Було складено інформацію у вигляді керівництва і для зручності користувачів її можна завантажити в блозі. Тип файлу – PDF. У результаті вийде:
-
-
- Content-Type: application/pdf
- Посилання: <http://сайт.ком/блог/canonical-tags/>; rel=”canonical”
-
Подібний алгоритм роботи можна застосувати в роботі з іншими сторінками.
Sitemap
Будь-яка пошукова система при налаштуваннях за замовчуванням аналізує посилання XML-файлу у вигляді канонічних. Деякі сервіси, такі як Google, роблять обов’язковою умовою застосування тільки канонічних адрес для карти сайту. Однак такий елемент виступає лише переліком рекомендацій. Деякі пошуковики його до уваги не беруть.
Використовуючи 301 (переадресацію)
Ще один варіант вирішення проблеми – застосування 301 редиректу. Він прийнятний, коли отримати доступ до сайту можна пройшовши за кількома адресами, включно з:
-
-
- https://сайт.ком/;
- https://www.сайт.ком/;
- http://сайт.ком/;
- http://www.сайт.ком/.
-
Перший варіант відзначається у вигляді канонічного, а в інших налаштовується переадресація.
Використання посилань у вигляді доповнення
Щоб визначити канонічну адресу, за словами Джона Мюллера, необхідні певні сигнали. Саме їх використовують пошукові системи. Наприклад, якщо представлено два варіанти адреси https://сайт.ком/ і http://www.сайт.ком/, то система Google зробить вибір на користь першого. При цьому, нерідко він віддає перевагу більш привабливій адресі. Наприклад, якщо відображено одне канонічне посилання, то система може обрати не його, а інше, більш оптимальне за її визначенням.
Якщо налаштування визначено неправильно, то це викличе серйозні проблеми в процесі індексації. За таких обставин оптимізатори припускаються кількох помилок у своїй роботі.
Неполадки в налаштуваннях canonical
-
-
- Правило однієї сторінки
- Головне правило для ефективного налаштування – 1 сторінка відповідає єдиній канонічній адресі. Якщо не дотримуватися такого правила і створити кілька, то є ризики ігнорування сторінки пошуковою системою. Тому важливо перевірити правильність налаштувань canonical. Для цього необхідно уважно вивчити реалізацію плагіна CMS.
- Одна сторінка – різні URL канонічного типу
- Незважаючи на схоже тлумачення з попереднім пунктом, суть у цьому інша. Вона пояснює, що в разі використання кількох способів вказівки canonical, необхідно переконатися, що посилання на головну сторінку в них єдине.
- Череда канонічних сторінок – головні налаштування
- Якщо для однієї основної сторінки вказано іншу основну сторінку, то пошукова система таку канонічну адресу в розрахунок брати не буде. Наприклад, для мойсайт.ком/1 є канонічне посилання мойсайт.ком/2, а для неї сайт.ком/3.
-
Розстановка rel = “canonical”
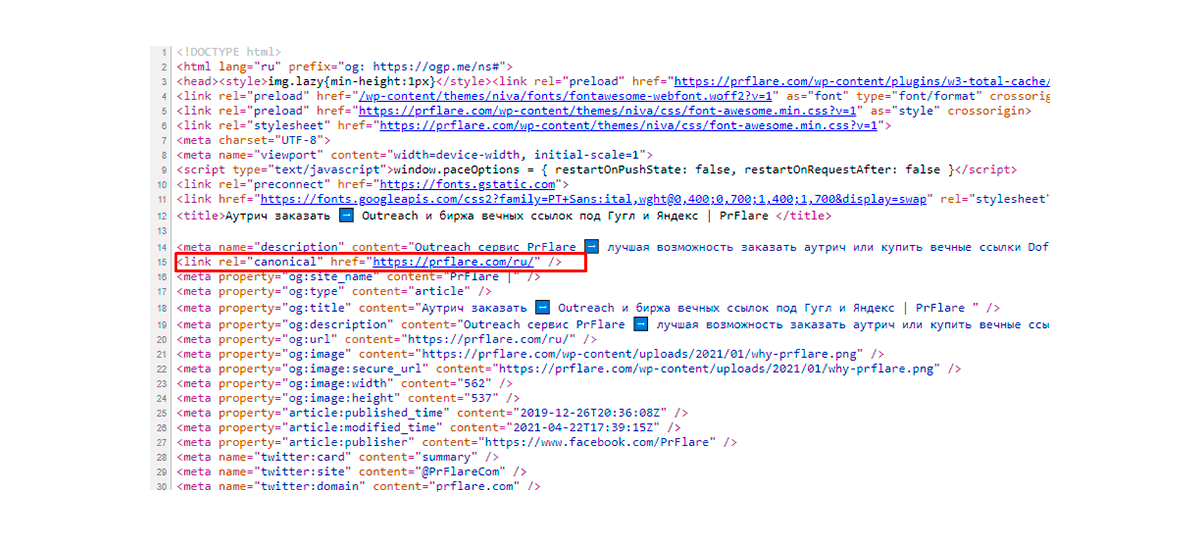
Тег rel = “canonical” має бути розміщений тільки в head. Якщо він поміщений в інші області, то пошуковий бот їх у розрахунок брати не буде. З’явиться ризик ігнорування всієї сторінки.
Перша сторінка пагінації – канонічна
Якщо з усіх сторінок пагінації тільки перша була вказана, як канонічна, то індексація інших буде виключена. У статті представлено кілька варіантів для виправлення ситуації, що склалася. Один із популярних – привласнення сторінці, що має пункт “Показати все” канонічний тип. Другий варіант – вказати індивідуальний canonical для кожної сторінки.
Однак є ймовірність виключення використання канонічного тега і припинення індексації. При цьому перехід буде доступний. Для цього необхідно:
-
-
- Використовувати disallow для /photo.
- Застосувати noindex або follow для пагінації.
-
Такий спосіб налаштування використовують у ситуаціях, коли є ризики негативного результату через використання всіх сторінок Pagination під час видачі з ідентичними Description і Title.
Канонічна URL – альтернатива 301 редиректу
Незважаючи на те, що функція 301 редиректу і тега canonical можна сказати, що ідентична, замінювати їх один одним не рекомендується. Перший спрямований на транспортування Traffic на одну сторінку, а другий на приховування від індексації. При цьому застосування rel = “canonical” не обмежить отримання трафіку або активність.
Основна сторінка виступає канонічною
Не рекомендується налаштовувати канонічне посилання таким чином, щоб воно було основним для сайту. Це призведе до того, що пошуковий бот ігноруватиме всі інші сторінки, звертаючи увагу на головну.
Наслідки приховування канонічної сторінки від індексації
Якщо бажана сторінка не індексується, то брати участь в утворенні результатів видачі вона не може. Цей самий результат настане і в разі наявності інших причин появи обмежень пошукової системи. За таких обставин буде обрано неканонічну сторінку.
Способи перевірки canonical
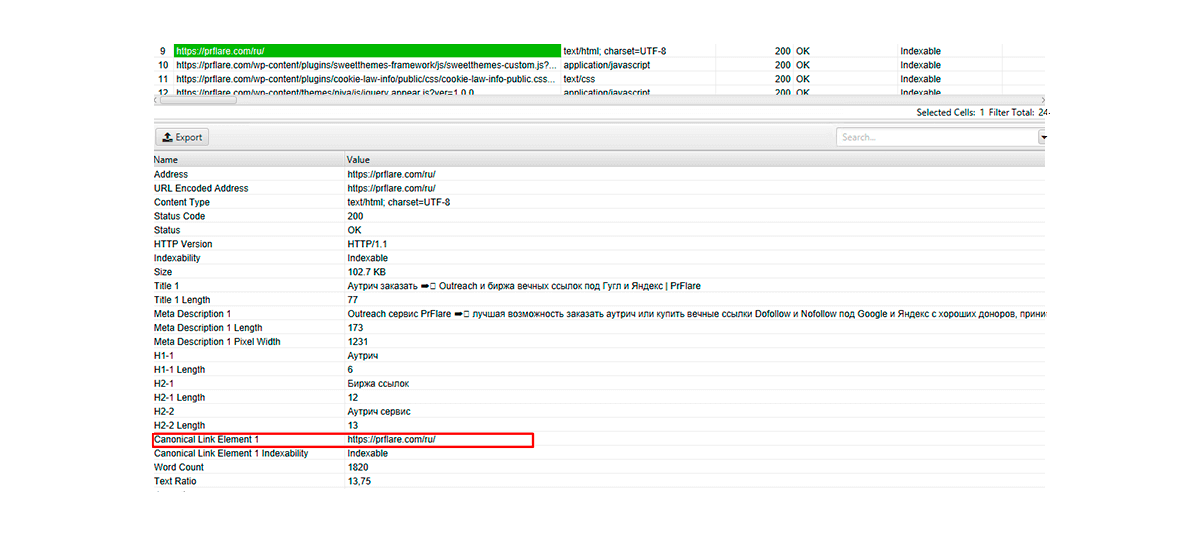
Щоб перевірити, чи правильно було здійснено налаштування сторінок канонічного типу, можна скористатися десктопною програмою Screaming Frog SEO Spider, у якій буде позначено сторінку, яку Google розпізнає як основну.
Для Яндекс шлях перевірки інший. Для таких цілей підійде Вебмайстер. Він прибере з пошуку всі дублі, залишивши тільки канонічне посилання. Відшукати таку інформацію можна в розділі “Індексування”. Усі виключені сторінки відображаються в однойменному розділі.
Наша думка
Вище наведені приклади показують, наскільки важливими є канонічні атрибути. Якщо у когось все ще є сумніви, чи працюють канонічні адреси, наведені вище випадки повинні розвіяти їхні сумніви. Якщо вам є що додати до розглянутої теми, то просимо вас поділитися своїм досвідом роботи з canonical на практиці в коментарях.



